こんにちは、研究チームの飯田です。今回は、CVPR2020にてSenseTime Group(香港)が発表した、仮想試着(Virtual Try-On)モデルの論文をご紹介いたします。
本記事では、画像ベースの仮想試着モデルの処理の流れを簡単に説明した後、タイトルのACGPN[1]について解説していきます。
はじめに
コロナ感染拡大防止のための自粛や寒波や花粉など季節の影響で外に出るのも難しい中、服を買いに店舗まで足を運んで試着するのは一苦労です。今回紹介する仮想試着システムは、撮影した自身の画像上で衣服を着せ替え可能という、店舗に行かずとも服選びをすることができるようになるものです。遠方で出向く事が難しい店舗の衣服も気軽に試着ができるようになるなんて便利ですよね。
これまでの仮想試着システムでは、ZOZOスーツのような方法で自身の3次元形状を計測する方法が採られていましたが、このような3次元形状を用いた方法はデータ収集の観点でコストが高くなるというデメリットがありました。
そこで近年では、画像ベースの仮想試着手法が隆盛を迎えています。画像ベースの手法は3次元形状を用いず、2次元画像のみで仮想試着を行う手法のため、よりコストを抑えて仮想試着モデルが構築できるようになります。一方で、利用できる情報が少なくなるため、生成される試着画像が不自然に歪んでしまう・ボケてしまうなど、性能面では課題が残っています。
本記事で紹介する論文は、上記の課題点を解消したAdaptive Content Generating and Preserving Network(以下、ACGPN)[1]という手法を提案した論文です。
画像ベースの仮想試着モデルのアプローチ
本節では、画像ベースの仮想試着モデルでよく利用されているアプローチを紹介しつつ、ACGPNではどうアプローチされているかを説明します。
最近出てきたVOGUE[2]などは趣向が違いますが、近年の仮想試着モデルは次の処理を行う傾向があると筆者は考えています。
- 試着者の画像から「人物表現」を抽出し、入力データ(+学習データ)を整形する
- 試着服を試着者にフィットするように変形する
- 試着者と試着服の画像(生成された一連の画像)を貼り合わせる
次図は、先行研究のVITON[3]と今回紹介するACGPN[1]のそれぞれに対応した処理と表現を例示したものです。
このように処理に若干の違いはありますが、大まかにはこの流れを汲んでいると考えると、近年の手法とACGPNのお気持ちが理解しやすくなると思います。次項から、それぞれの処理の中身を説明していきます。

1. 人物表現(Person Representation)
まず、仮想試着モデルを学習する際に問題となるのは学習データです。試着対象者が同じ撮影条件で服だけ異なる画像データを収集するのは困難です。
これに対して、CVPR2018で発表されたVIrtual Try-On Network(以下、VITON)[3]では、入力データを「特定の衣服に依存しない人物表現」に抽象化することでこの問題を解決しました。その人物表現に元々着用していた服を試着させるような学習をすることで、新たな学習データを用意することを回避しました。VITONが登場したことで、画像ベースの仮想試着モデルが広がり始めた形です。
この表現は後続のCP-VTON[4]でも利用されていますが、服だけでなく人物の情報全体を抽象的にしてしまうので、生成される人物や服との境界が不自然になってしまう問題や本来生成しなくても良い領域を生成してしまう問題があります。
次図はVITONの人物表現と結果画像です。結果の試着後の画像のように、生成される領域が曖昧になっており、制御できていません。
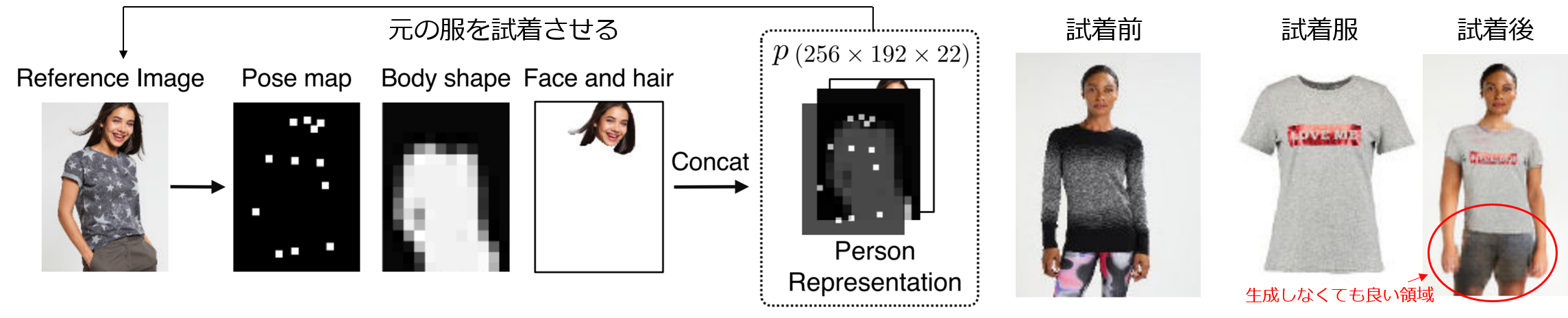
一方で、VTNFP[5]や今回紹介するACGPNでは、試着対象者の姿勢や体型のレイアウトで保存する場所と新たに生成する場所を切り分けています。レイアウトを切り分けることで、これまで輪郭などの抽象化していた人物表現を明確にできます。また、生成する箇所を少なくすることで、上図の不自然な手や下半身の領域を除去しています。※後述
2. 試着服の幾何学的変形
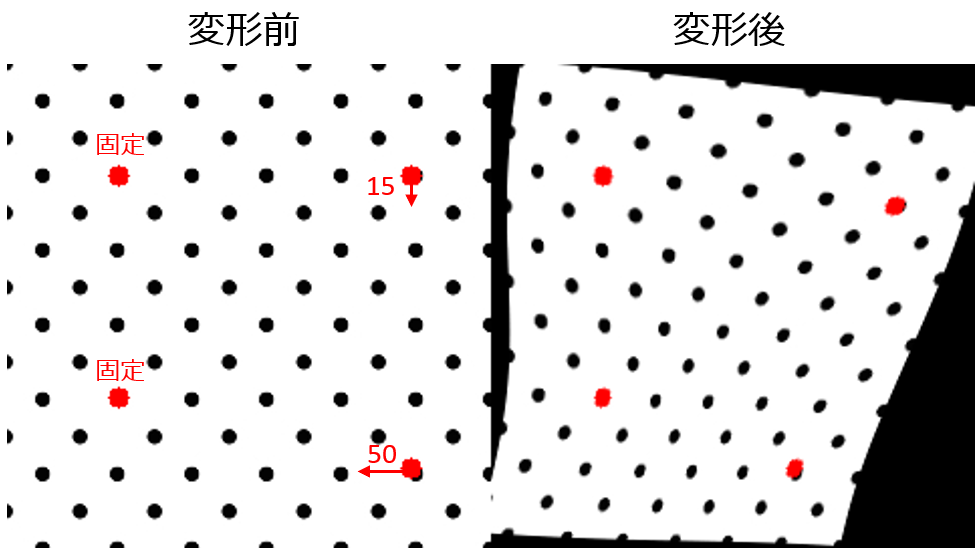
試着服を試着者にフィットさせる際には、新たな服画像の生成ではなく、元のテクスチャを保持できるように試着服を幾何学的に変形させます。幾何学的変形には、アフィン変換や透視変換などがあると思いますが、仮想試着では薄板スプライン変換(Thin Plate Spline、以下TPS変換)[6]が利用されます。TPS変換は簡単に言うと、画像を一枚の薄板とみなし、あるピクセルを別の座標に移動させたら周囲のピクセルがどう移動するのかを計算する方法です。
実際に利用する際には、画像上でグリッドを用意して、各点の移動前後のマッチングを取り、それらの変位のスプライン補間を行うことで画像のピクセル全体の移動量を求めます。下図はTPS変換の例で、赤4点のうち左2点を固定し右2点を矢印ピクセル分変位させた時のTPS変換です。
仮想試着では、TPS変換で試着服画像を変形する際、グリッドを変形後の試着服のマスクにどうマッチングさせるかが課題になります。先行研究のVITON, CP-VTON, VTNFPでは、次のようなアプローチでマッチングを取っています。
-
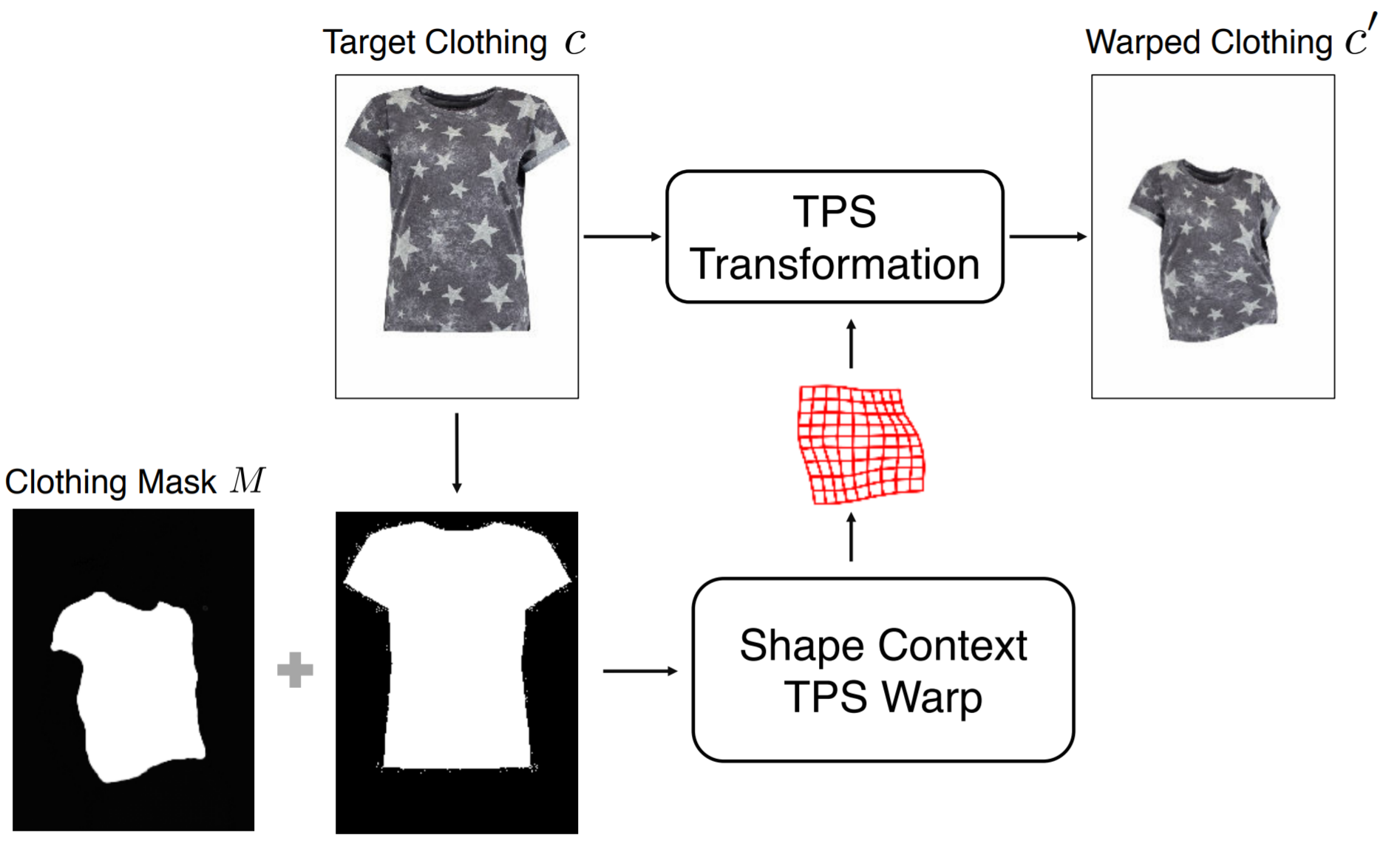
VITON
試着者が元々来ていた服のマスク画像と試着服の変形後のマスク画像とで、Shape Context Matching[7]を計算し、TPS変換の対応点のマッチングを行います。 -
CP-VTON, VTNFP
CP-VTONでは、SIFT特徴量などの局所記述子を使って、人物表現画像と試着服との特徴マッチングを取り、回帰ネットワークを使用して、TPS変換のパラメータを推定する学習ベースの方法(Geometric Matching Module(GMM))を採っています。VTFNPでは、このGMMにNon-Local(NL)ブロック[8]を追加して、特徴学習やマッチングを改善しています。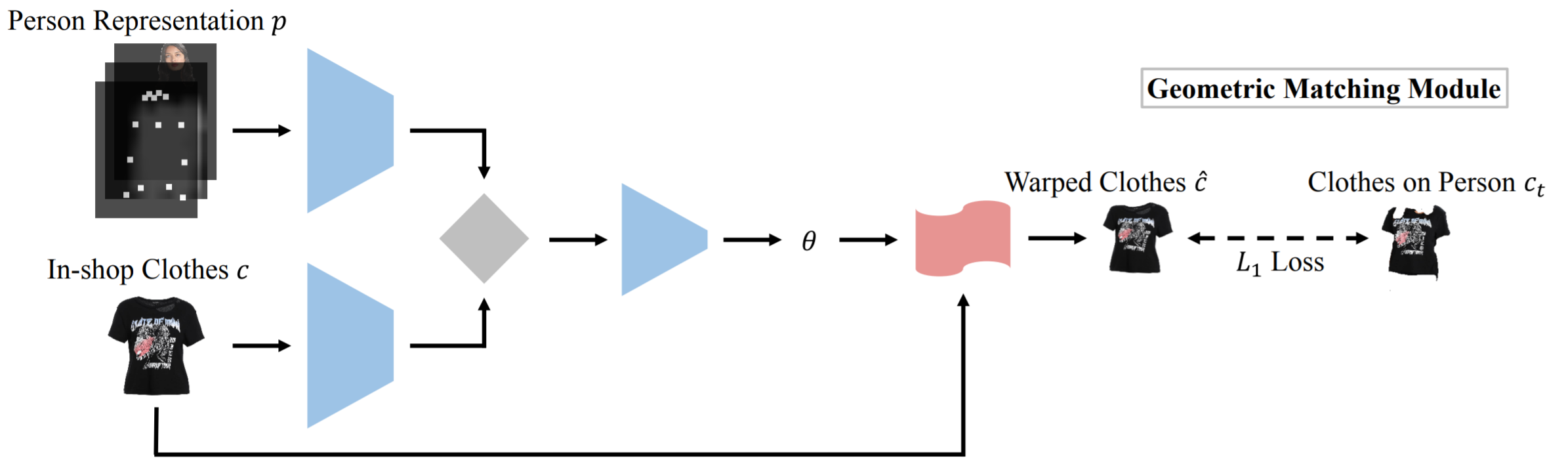 CP-VTON [4, SenseTime]
CP-VTON [4, SenseTime] -
ACGPN
ACGPNでは、Spatial Transformer Networks(以下、STNs)[9]を利用して、TPS変換のパラメータを学習ベースで求めます。さらに、SPNsの損失にTPSのグリッドを極力保存できるような二次微分成約を加えることで、局所的に不自然に歪む箇所を除去しています。※後述
3. 各パーツの貼り合わせ
仮想試着モデルでは、試着者のパーツごとに別々に画像を生成(もしくは保存)することが多いため、最終的にそれらを貼り合わせる必要があります。仮想試着モデルによって、生成されるパーツが異なるため、合成方法もさまざまです。
VITONではパーツ毎に生成するのではなく、1ステージ目で生成される荒い結果画像と2ステージ目で生成される詳細な服の画像をブレンドするマスク行列を学習しています。CP-VTONでは、U-Netとマスク行列の組合せ、VTFNPでは、Attention-Gated U-Netとマスク行列の組合せを生成パーツに掛けて貼り合わせを行っています。ACGPNはConditional GANを使って貼り合わせを行っています。
ACGPN
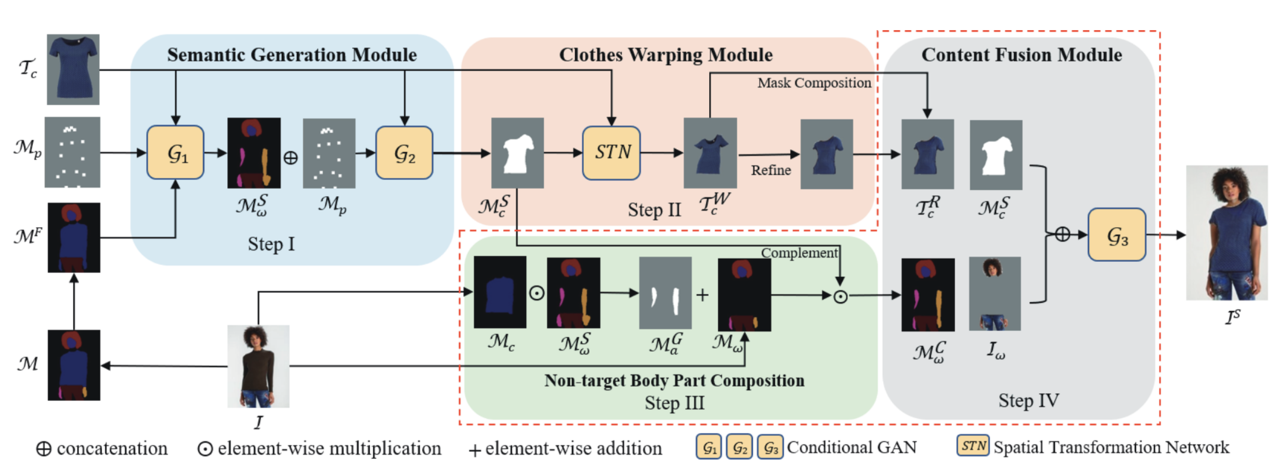
概要
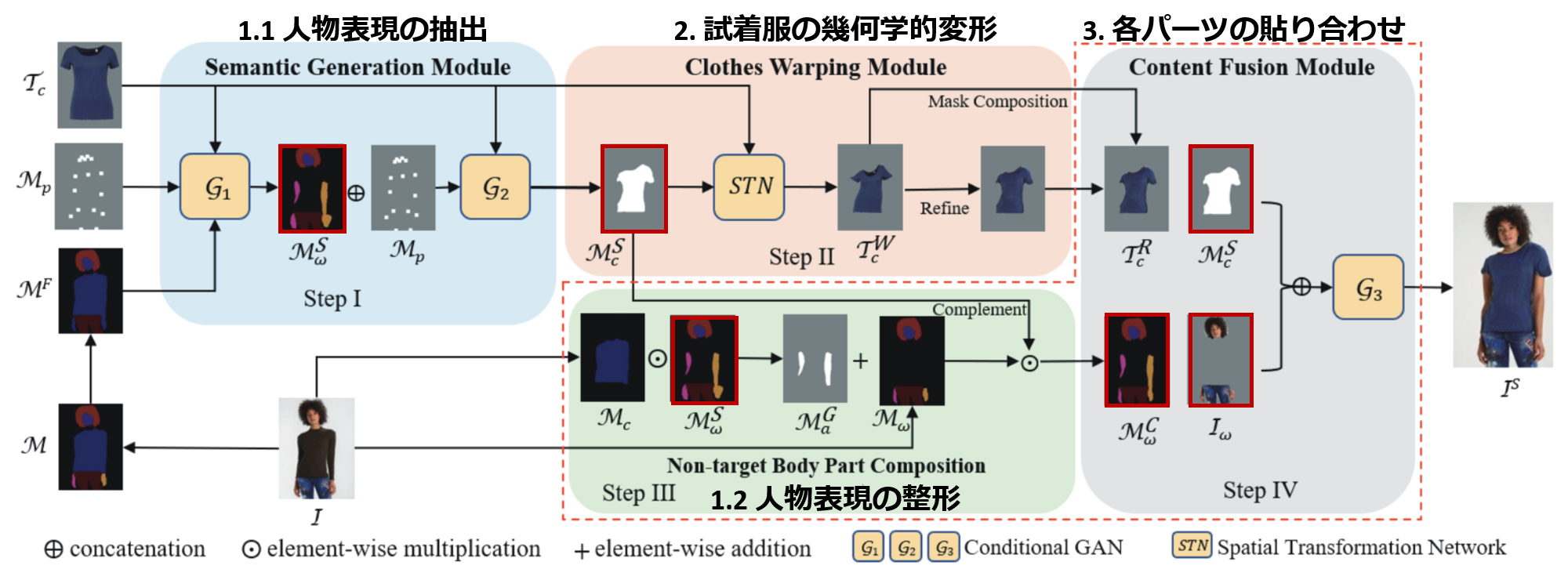
本記事のメインで紹介するACGPNの論文について解説します。上図はACGPNの処理パイプラインです。人物表現を構築する際のプロセスが分かれているので複雑に見えますが、前節で説明してきたように、主には「人物表現の抽出」「試着服の幾何学的変形」「貼り合わせ」の処理を行っています。
-
Semantic Generation Module (SGM)
試着前の画像 $I$ と試着服 $T_c$ の画像から試着後の服 $M_c^S$ や体のパーツのレイアウト $M_p$ を決定します。 -
Clothes Warping Module (CWM)
SGMから受け取った試着後の服の領域 $M_c^S$ にマッチするようにTPS変換のパラメータの学習と変換を行います。 -
Non-target Body Part Composition
試着前の画像 $I$ とSGMで生成した $M_c^S$, $M_p$ を使って、試着前の画像からそのまま試着後の画像に保存領域の切り出しを行います $I_w$。 -
Content Fusion Module (CFM)
試着前後で(服により)オクルージョンがあった体のパーツを生成を行い、さらにこれまで生成してきた服と体のパーツの貼り合わせを行います。
ACGPNでは、大きく2つの工夫があると思います。
1つは人物表現です。試着者のパーツを保持領域、試着服領域、生成領域を適応的に切り分けて仮想試着を行う際の影響を極力抑えたことです。さらに、VITON, CP-VTONのような人物表現と異なり、輪郭をぼかさない人物表現に変えたことで、はっきりとした試着画像を生成することができています。

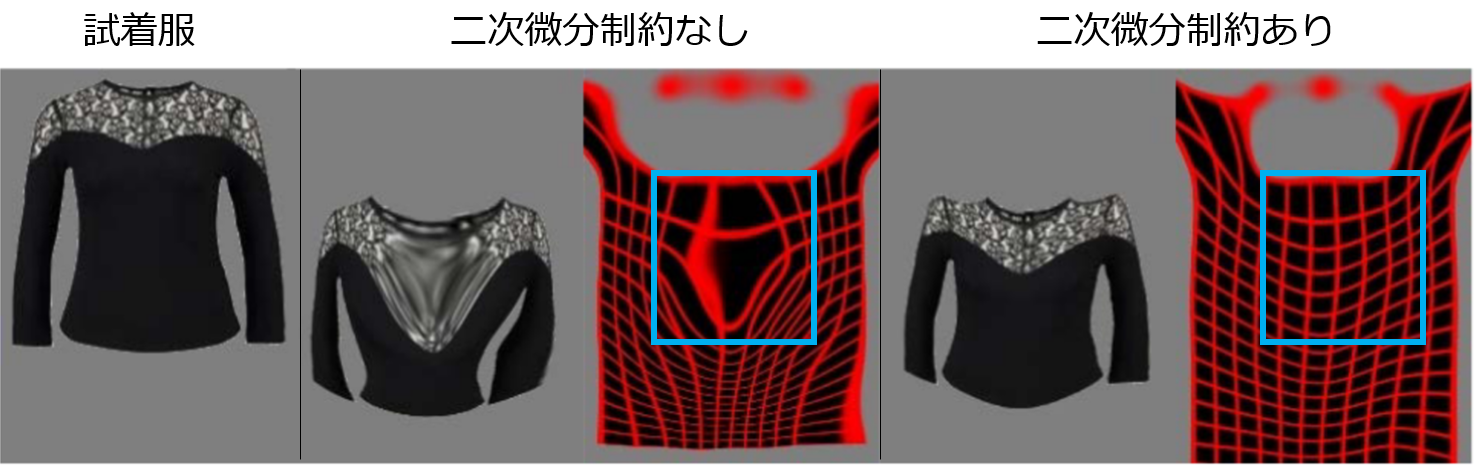
もう1つは、TPS変換するパラメータに二次微分制約を導入し、服の不自然な歪みを解消することで、試着服の細かな刺繍などを自然な形で変形できるようにしたことです。これは簡単にいうと、TPS変換をする際のメッシュの格子関係をキープするような制約であり、各格子の縦横の長さの均一性や角度の急激な変化にペナルティを課しています。
次図は、制約を入れた場合の服の変形結果です。青枠で囲ったように、二次微分制約を導入することで、メッシュが保たれています。
結果
次図は比較結果の1例です。ACGPNは既存手法に比べ、服の歪み(上段)や試着に関係の無い手の領域が明瞭に保持されていることが確認できます。

論文や実装もありますので、ぜひご覧ください。
中国語が読める方はSenseTime Groupのページでも解説をしているので、こちらもご参照ください。
参考文献
[1] Han Yang et al. "Towards Photo-Realistic Virtual Try-On by Adaptively Generating↔Preserving Image Content". CVPR, 2020.
[2] Kathleen M Lewis et al. "VOGUE: Try-On by StyleGAN Interpolation Optimization". arXiv preprint arXiv:2101.02285, 2021.
[3] Xintong Han et al. "VITON: an image-based virtual try-on network". CVPR 2018.
[4] Bochao Wang et al. "Toward characteristicpreserving image-based virtual try-on network". ECCV, 2018.
[5] Ruiyun Yu et al. "VTNFP: An Image-Based Virtual Try-On Network With Body and Clothing Feature Preservation". ICCV, 2019.
[6] Jean Duchon. "Splines minimizing rotation-invariant seminorms in sobolev spaces". In Constructive theory of functions of several variables, pages 85–100. Springer, 1977.
[7] Serge Belongie et al. "Shape matching and object recognition using shape contexts". IEEE TPAMI, 2002.
[8] Xiaolong Wang et al. "Non-local neural networks". CVPR, 2018.
[9] Max Jaderberg et al. "Spatial transformer networks". NIPS, 2015.
投稿者プロフィール
最新の投稿
- 2021.12.22STJOKdoの格安LiDARで遊んでみた
- 2021.12.14STJセンスタイムのXRソフトウェアプラットフォーム「SenseMars」のAR技術について
- 2021.12.10STJ品質よもやま話(その2)~おいしい「品質」~
- 2021.12.09STJ品質よもやま話(その1)~「品質」っておいしいの?~

