こんにちは、センスタイムジャパンの畠山です。本記事では、SenseTime ResearchによるDNN枝刈り(Pruning)手法に関する論文 "DMCP: Differentiable Markov Channel Pruning for Neural Networks" [1] の内容を紹介します。こちらの論文は、IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020にてオーラル発表として採択されています。
はじめに
本研究では、DNN枝刈り手法である Differentiable Markov Channel Pruning (DMCP) を提案しています。DMCPでは、 各層のチャネルを番号付けした上で、番号が小さい部分に重要な情報が集中するように重みの学習を行い、枝刈り後にチャネルが残存する確率と交互に学習を行う ことで、効果的な枝刈りを行うことができます。
DNN枝刈りについて
まずはじめに、DNN枝刈りの概要について紹介したいと思います。
学習によって得られるDNNの内部表現は、必ずしも全てが等しく重要であるとは限りません。例えば、あるチャネル(ニューロン)に対応する重みの絶対値が非常に小さい場合を考えてみます。この場合、このチャネルは活性化していたとしても非常に小さな値しか出力しないため、次の層の出力、ひいてはモデル全体の出力に大きな影響を与えないと予想されます。つまり、このようなチャネルは推論結果に対する重要度が低いチャネルだと考えられます。
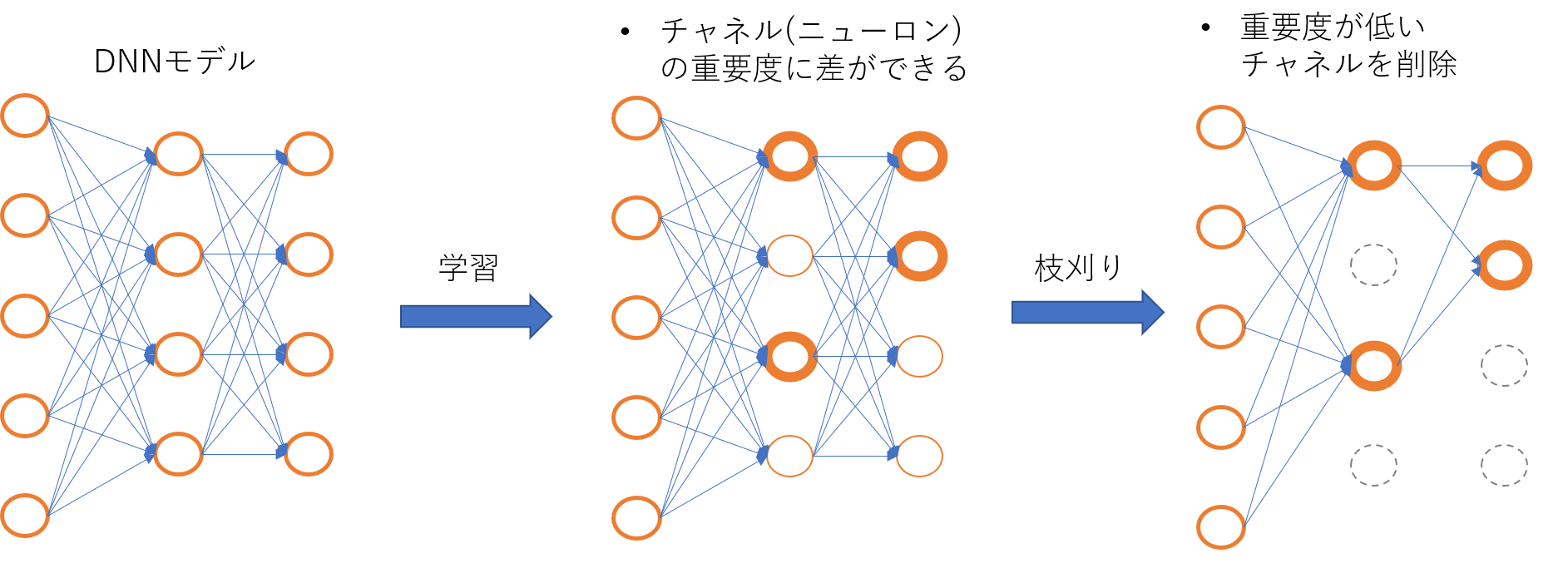
DNN枝刈りでは、大きなDNNモデルを学習した後、内部にある重要度が低いチャネルや重みを削除し、重要度が高いもののみを残す事を目指します(図1)。枝刈りを行うことで、モデルを保存するストレージサイズ、推論にかかる時間・メモリ量・消費電力等のリソースの削減が見込めます。特に、リソースの制約が厳しい組み込みシステム・モバイルデバイスへDNNモデルを実装しようとする場合には、枝刈りによるリソース削減は非常に重要になります。一方で、枝刈りを行うと一般的にモデルの認識精度が低下してしまうため、どれだけ精度低下を抑えつつリソース消費量を削減できるか、ということが枝刈り手法において重要な課題となります。
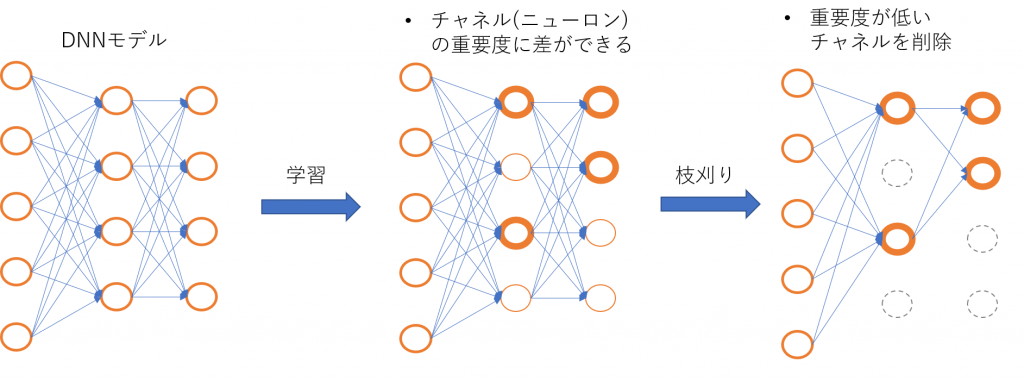 図1: DNN枝刈りの概念図
図1: DNN枝刈りの概念図
ところで近年の研究では、「枝刈りの結果で重要なのは得られたネットワーク構造そのものであり、学習したモデルの重み自体は精度を保つために必ずしも必須ではない」事を示唆する結果が報告されています[2]。これを受けて、ネットワーク構造探索(Neural Architecture Search)の手法と枝刈りを関連付けるアプローチも研究されています。本研究もこのような流れに沿った研究になります。
DMCPの説明
本研究では、枝刈りのチャネル削除プロセスのパラメータ化を工夫する事で、構造探索を行うパラメータ空間を大幅に削減し、層ごとの最適なチャネル数を効率的に探索する事を可能にしました。
DMCPの主要なアイデアをまとめると以下のようになります(図2):
- (1) 各層の出力チャネルに連番で番号をつけ、番号が小さいチャネルほど、精度を上げるために重要な情報が集中するように工夫して学習を行います(詳細は後述)。
- (2) 枝刈りを行う際は、残すチャネル数より小さい番号のチャネルを全て残し、それより大きい番号のチャネルを全て削除します。
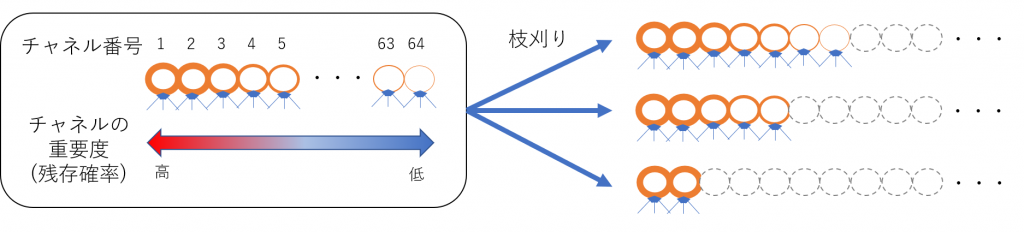 図2: DMCPでのチャネル削除プロセス
図2: DMCPでのチャネル削除プロセス
チャネル削除プロセス
(2)のチャネル削除プロセスによって探索空間が大幅に削減されます。例えば64チャネルの層を例にあげてみます。通常の枝刈りでは各チャネルごとに削除するかしないかの選択が行われるため、約2^64(>1000京)通りの選択肢が存在します。一方DMCPでは、高々残すチャネル数(=64)通りの選択肢しかなく、大幅に探索空間が削減されている事がわかります。
このチャネル削除プロセスは、確率モデルであるマルコフ過程によって微分可能な形でパラメータ化することができます(この事が手法の名称の由来になっています)。このパラメータ化によって、「各チャネルが削除されずに残存する確率」(=チャネルの重要度)を勾配降下法によって学習させる事ができます。
また、このチャネル削除プロセスは実装面においてもメリットがあります。通常の枝刈りでは、削除されるチャネルの位置がバラバラであるため、チャネル削除後には通常の畳み込み演算の実装をそのまま適用できません。通常の畳み込み演算実装を使って推論高速化・消費メモリ削減を行うためには、「削除されたチャネルの隙間を詰める」必要がありますが、層をまたいだチャネル間の接続構造を壊さないようにこれを行うのは(特に分岐・合流があるモデルでは)かなり大変になります。一方DMCPでは、チャネルを削除しても「隙間」が生じないので、このような場合のチャネル削除も比較的シンプルに実装できます。
重みの学習手法
一方で、単純に上記のような仕方でチャネル削除をしてしまうと、番号が大きいチャネルに重要な情報があった場合に精度が大幅に低下してしまいます。それを防ぐため、((1)で述べたように)重みの学習の仕方を工夫する事で番号が小さいチャネルに重要な情報が集まるように仕向けます。
具体的には、以下に説明する 「(variant) sandwitch rule」 による学習を行います[1,3]。この学習方法では、
- 実際にチャネル削除を行ったモデルを(残すチャネル数を変えながら)複数生成する。
- それらのモデルの出力結果から損失を計算し、それぞれのモデルで使用したチャネルのみに対して重みを更新する。
という事を行います(図3)。
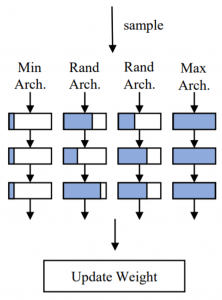 図3: (variant) sandwitch rule [1]
図3: (variant) sandwitch rule [1]
ここで、チャネル数最大のモデル(枝刈りしないモデル)とチャネル数最小のモデル(最大チャネル数の1/10程度のチャネル数)は必ず生成し、他のモデルは(現時点でのチャネル残存確率に基づいて)残すチャネルの数を層ごとにランダムに決定します。
このようにして重みの更新を行うと、番号が小さいチャネルは番号が大きいチャネルよりも削除されずに残る確率が高いため、頻繁に損失の計算と重みの更新が行われます。その結果、損失を大きく下げるために必要な情報が番号が小さいチャネルに集まるように学習が進む事が期待されます。
枝刈り
以上のように重みの学習を行う事で、番号が小さいチャネルに重要な情報が集まり、番号が大きいチャネルを削除しても精度が低下しづらくなります。その結果、チャネル残存確率の学習においても、番号が大きいチャネルで残存確率が低くなるように学習が進みます。このような重みの学習とチャネル残存確率の学習を交互に行うことで、実際にチャネル削除を行った際の精度低下を抑えつつ多くのチャネルが削除可能になるようなモデルが学習されます。
最後に、重みとチャネル残存確率の学習が完了したら、各層ごとに「残存するチャネル数の期待値」を求め、その分のチャネル数を残してチャネル削除を行う事で最終的なモデル構造を得ます(Expected sampling)。
実験結果
次に、論文での実験結果の紹介に移ります。表1は、ImageNetデータセットでのDMCP手法による枝刈り学習の結果をまとめたものです[1]。比較対象として、単純にモデル全体のチャネル数を一様な割合で削減した場合と、他のDNN枝刈り手法であるMetaPruning[4]・AutoSlim[5]の結果を載せています。
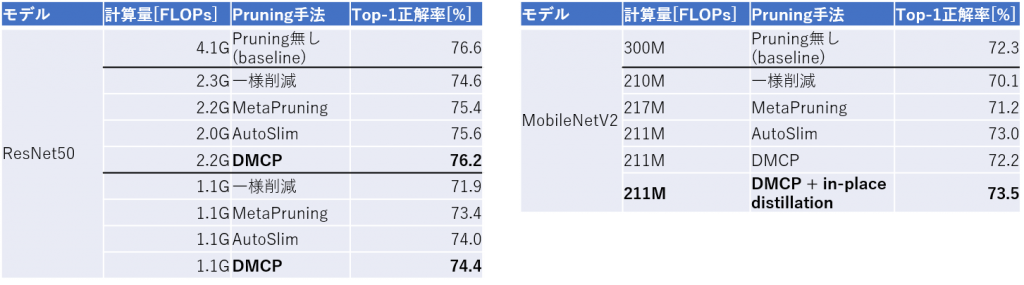 表1: ImageNetデータセットでの学習結果
表1: ImageNetデータセットでの学習結果
ResNet50モデルでは、計算量を約半分(2.2GFLOPs)まで削減してもTop-1精度の低下が0.5pt以下に収まっており、約1/4(1.1GFLOPs)まで削減しても高い精度を保っている事が分かります。
MobileNetV2モデルでは、元々計算量がかなり小さくなるよう最適化されたモデルであるにも関わらず、1/3近い計算量をほとんど精度低下なく削減できています。さらに、AutoSlim[5]で提案されたin-place distillation手法と組み合わせることで、AutoSlimやbaselineのモデルをも上回る精度を達成しています。
今回紹介したDMCP法について、紹介しきれなかった詳細部分等については、原論文[1]を御覧ください。
また、githubにて学習コード (Pytorch) が公開されていますので、ご興味がある方は是非試してみてください。
参考文献
[1] S. Guo, Y. Wang, Q. Li, and J. Yan, “DMCP: Differentiable Markov Channel Pruning for Neural Networks”, in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020, pp. 1536-1544.
[2] Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell, “Rethinking the Value of Network Pruning”, in International Conference on Learning Representations (ICLR) 2019.
[3] J. Yu and T. S. Huang, “Universally Slimmable Networks and Improved Training Techniques”, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2019, pp. 1803-1811.
[4] Z. Liu et al., “MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning”, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 3296-3305.
[5] J. Yu and T. Huang, “AutoSlim: Towards One-Shot Architecture Search for Channel Numbers”, arXiv:1903.11728.
投稿者プロフィール
-
研究開発センター 研究チーム所属 リサーチャー。博士(理学)。
趣味は主に科学関係の読書。
最新の投稿
- 2022.06.01STJ統計検定1級受験記
- 2021.12.17STJRendering 3D Fractals by Sphere Tracing
- 2021.12.13STJエッジAIコンピューティングについて
- 2021.10.06STJセンスタイムによるCVPR2020発表論文: DNN枝刈り(Pruning)手法 「DMCP」を紹介します

