こんにちは。2022年4月からセンスタイムジャパンのインターンでお世話になっております、加藤と申します。今回インターンで取り組んだ研究成果を2022年7月25日~7月28日に開催された第25回 画像の認識・理解シンポジウム(MIRU2022)にて発表致しました。本記事ではその内容 『Lite-HRNet Plusを用いた高速・高精度な顔ランドマーク検出』について解説したいと思います。
はじめに
研究背景

図1 顔ランドマーク検出の例
顔のランドマーク検出(図1)とは、顔器官情報を取得することができる技術です。この技術は、顔認証、頭部姿勢推定、顔画像生成、3D顔再構成など様々なタスクに応用することができます。
近年、ドライバーの安全・快適をサポートするADAS(Advanced Driver-Assistance Systems、先進運転支援システム)という技術では、ドライバーの視線や頭部の向き等を推定することによって異常状態を検知し、交通事故を事前に防ぐことを目的の一つとしています。このような推定を行うためには、ドライバーの顔器官情報(顔ランドマーク)を自動で認識する必要があります。
実際の環境下では、限られた計算リソースを用いてリアルタイムでドライバーの顔を認識する必要があるため、軽量で高速推論可能な顔ランドマーク検出手法が求められています。
Lite-HRNet
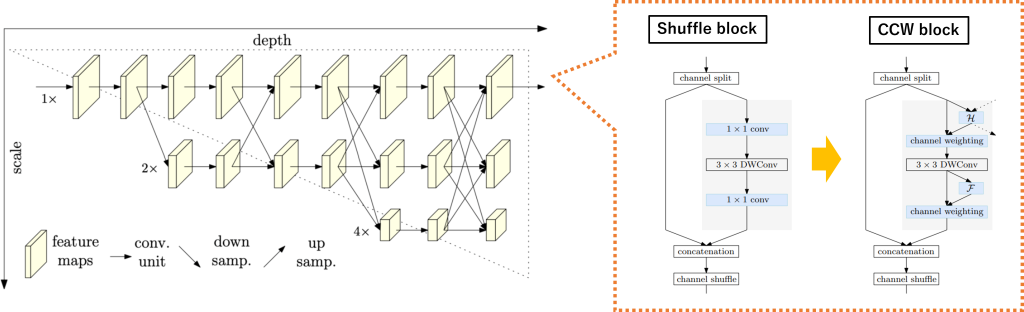
図2 Lite-HRNetの概要図
近年の画像認識分野では、あらゆるタスクでConvolutional Neural Network(CNN)を用いた手法が高精度を達成する手法として知られています。その中でもよりリアルタイムな推論を考慮した、Light-weightなモデルの研究が進んでいます。特に、画像認識分野のトップカンファレンスであるCVPR2021で提案されたLite-HRNet [1]は、人物の関節点や姿勢を高速かつ高精度に推定することができる強力なモデルです(図2)。
Lite-HRNetでは、高解像度・低解像度のサブネットワークを並列に接続して学習を行うHR-Netに、ShuffleNetv2 [2]で提案されたShuffle blockを追加することでモデルの軽量化を達成し、さらにShuffle blockに解像度間方向とチャンネル方向のAttention block(CCW block)を追加することで、精度向上を達成しています。
姿勢推定タスクと顔ランドマーク検出タスクの学習方法と推論方法に違いはほとんどないため、Lite-HRNetは顔ランドマーク検出にそのまま適用することが可能です。本研究ではこのLite-HRNetをベースモデルとしています。
Lite-HRNet Plus(提案手法)
更なる高速化・高精度化を達成するため、本研究ではLite-HRNetの欠点を改良した、Lite-HRNet Plusを新たに提案しています。Lite-HRNet Plusは3つの提案手法から成り立っています。
1. Stepped Channel Attention block
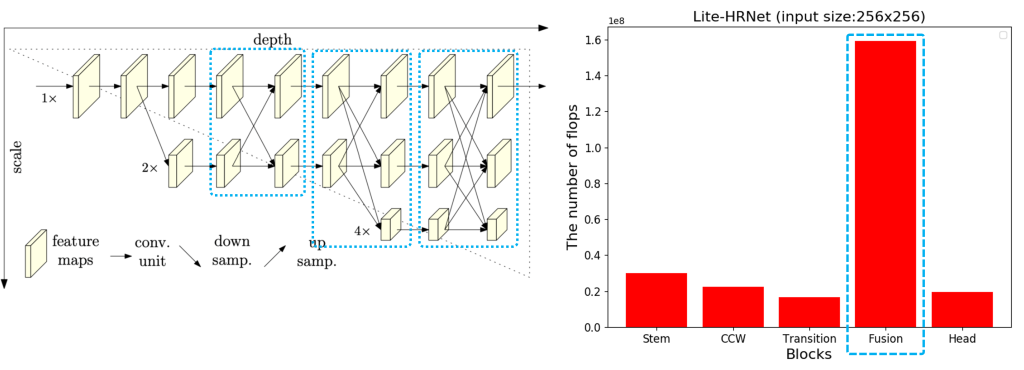
図3 Lite-HRNetの各blockの計算量比較(縦軸 : FLOPs, 横軸 : 各bolck)
まず最初に考えられる問題点はLite-HRNetの計算量についてです。Lite-HRNetのネットワークを構成しているblockの計算量をそれぞれ解析した結果、図3に示すように異なる大きさの特徴マップを接続するFusion blockが最も計算量が大きいことを発見しました。このFusion blockでは異なる解像度特徴マップ間のチャンネル数を揃えるため、チャンネル方向のみを演算対象としたPoint-wise convolutional layerを使用しています。このlayerの計算量は扱うチャンネル数が多くなるほど大きくなるため、結果Fusion blockの計算量が膨大になります。
そこで、Point-wise convolutional layerを一切使用しない新たなFusion blockとして、Stepped Channel Attention (SCA) blockを提案しています(図4)。
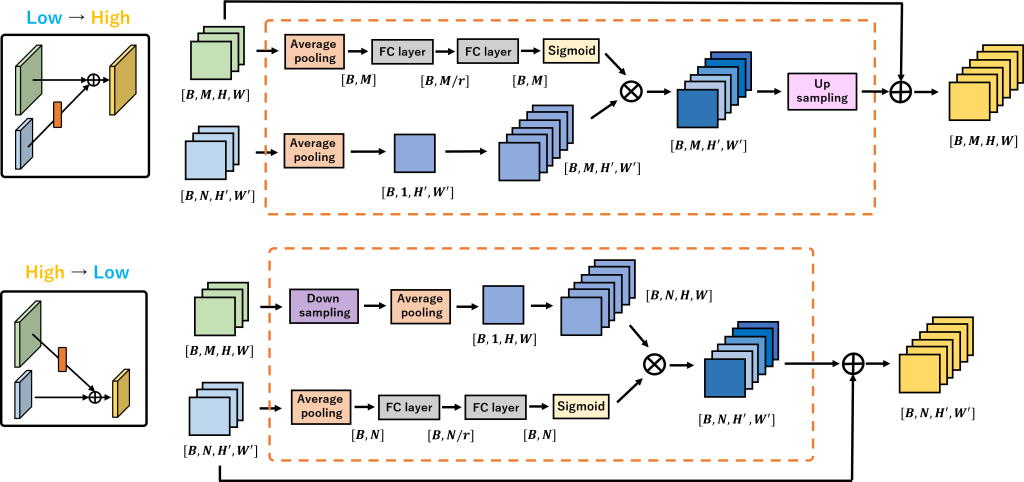
図4 Stepped Channel Attention blockの概要図
通常の畳み込み演算ではあらかじめ重みを用意しておく必要がありますが、SCA blockではChannel attentionによって生成される重みで代用しているため、その分の計算量が削減できます。平均化された特徴マップにChannel attentionで計算した重みを掛け合わせることで、接続先の特徴マップと同じチャンネル数を持った新たな特徴マップを生成することが可能になります。これはPoint-wise convolutional layerの限定的なケースを再現していることになります。SCA blockはPoint-wise convolutiona layerよりもやや表現力は落ちてしまいますが、Lite-HRet Plusではモデル全体のチャンネル数を増やすことで表現力低下を防いでいます。これにより、精度低下をなるべく抑えつつ、計算量を大幅に削減することが可能となります。
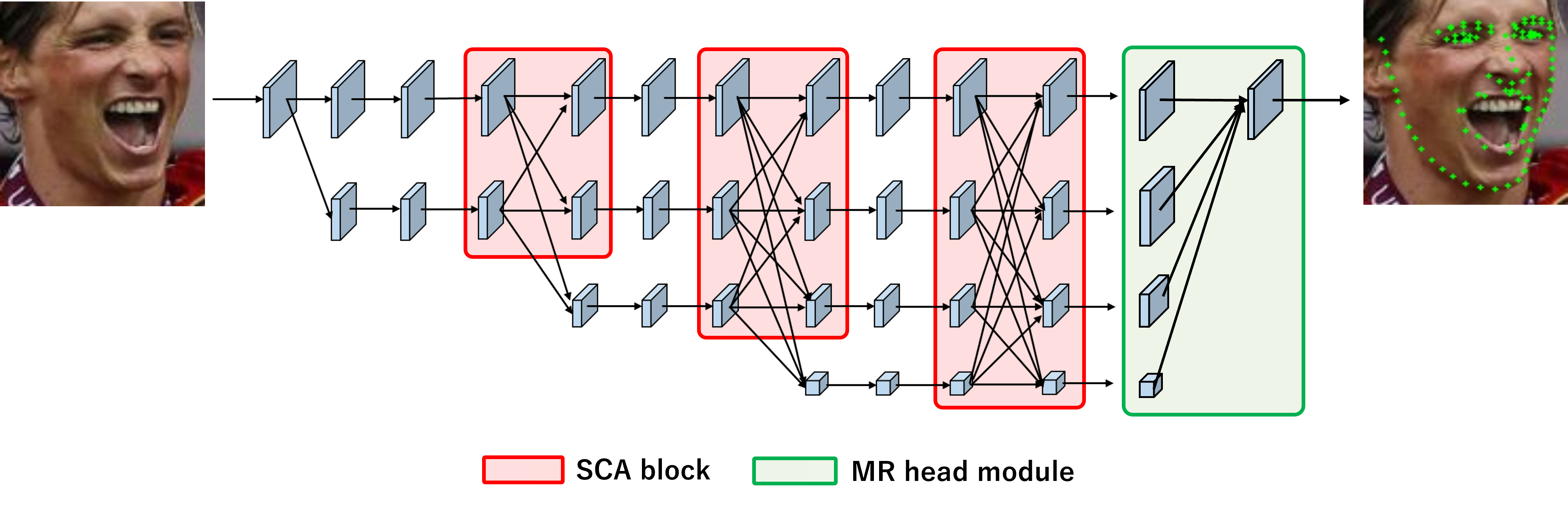
2. Multi-Resolution head module
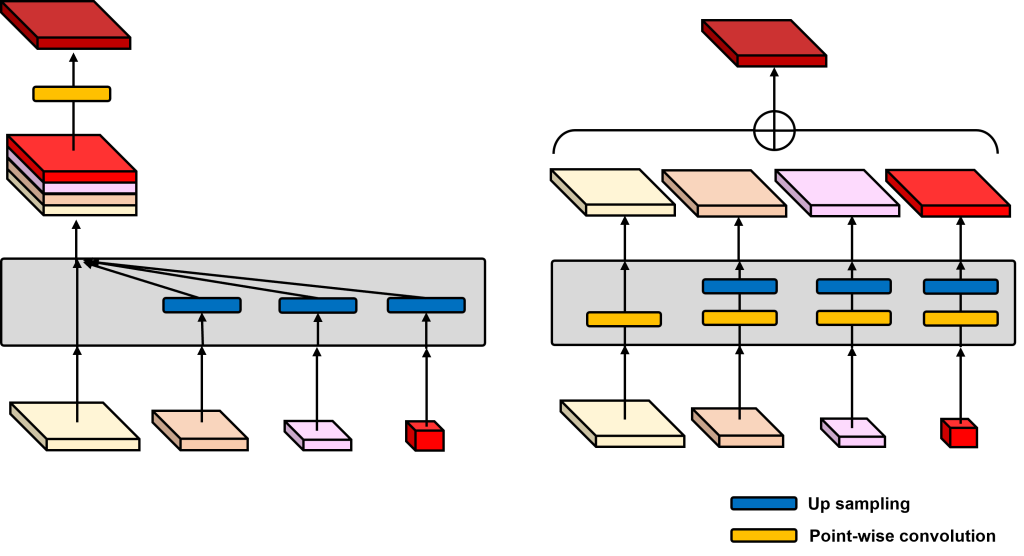
図5 左はHRNet-V2 head moduleの概要図、右はMulti-Resolution head moduleの概要図
先行研究のHR-Net [3]を更に発展させたHRNetV2 [4]では、最終出力において単一の特徴マップだけではなく、異なる解像度の特徴マップを用いて最終予測を行っています(図5左)。これにより、顔ランドマーク検出において高い精度を達成することが確認できています。この出力方法はLite-HRNetでも用いることが可能ですが、HRNet-V2ではすべての解像度の特徴マップをconcatしており、膨大なチャンネル数を扱う必要があります。これは理論計算上、元のHRNetに比べ約15倍の計算量増加に繋がります。そこで異なる解像度の特徴マップを扱うかつ、計算量を増やさない新たな出力モジュールとしてMulit-Resolution (MR) head moduleを提案しています(図5右)。MR head moduleではconcatを用いず、各解像度の特徴マップから最終予測を出力し、アップサンプリングして足し合わせる処理をしています。MR head moduleはHRNetの出力手法と比べ計算量の増加は僅か1.87倍で済むため、HRNet-V2よりも計算量を削減することが可能です。
3. Loss function
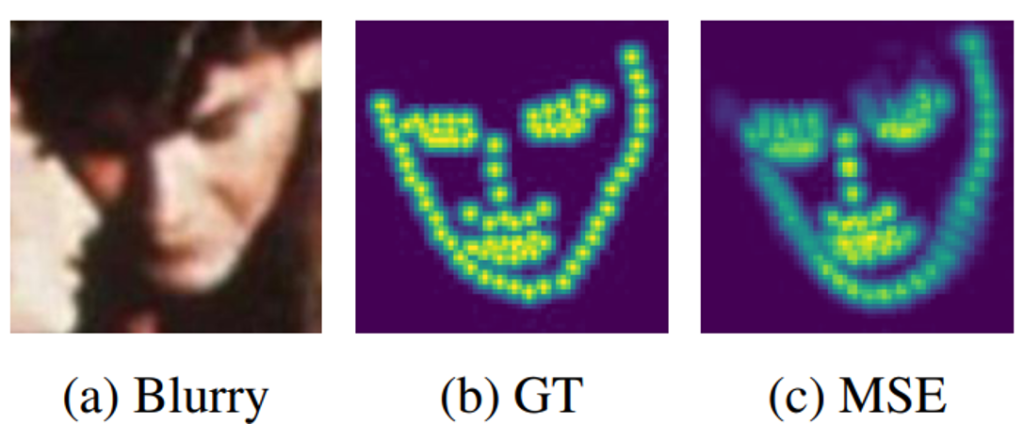
図6 MSE lossを用いた学習結果(画像は参考文献[5]から引用)
従来の姿勢推定や顔ランドマーク検出の学習では用いられてきた損失関数は多くの場合Mean Squared Error loss (MSE loss)でした。しかしMSE lossを用いた時、出力はぼやけたヒートマップになりがちでになることが既に報告されています [5](図6)。これはMSE lossが小さな誤差に対して敏感ではないため、ガウス分布のモードを正確に推定できないことが原因であり、これを回避するような損失関数 [5]も提案されていますが、MSE lossの枠に収まっている手法がほとんどです。
Lite-HRNet PlusではMSE lossベースの損失関数ではなく、単純なBinary Cross Entropy loss (BCE loss)を用いた学習を提案しています。BCE lossを用いることで、グラフに示すように予測と正解の差が大きい時も小さい時でも、MSE lossよりも大きなLossを発生させることが可能です(図7)。この結果教師のガウス分布に近づきやすくなると考えられます。
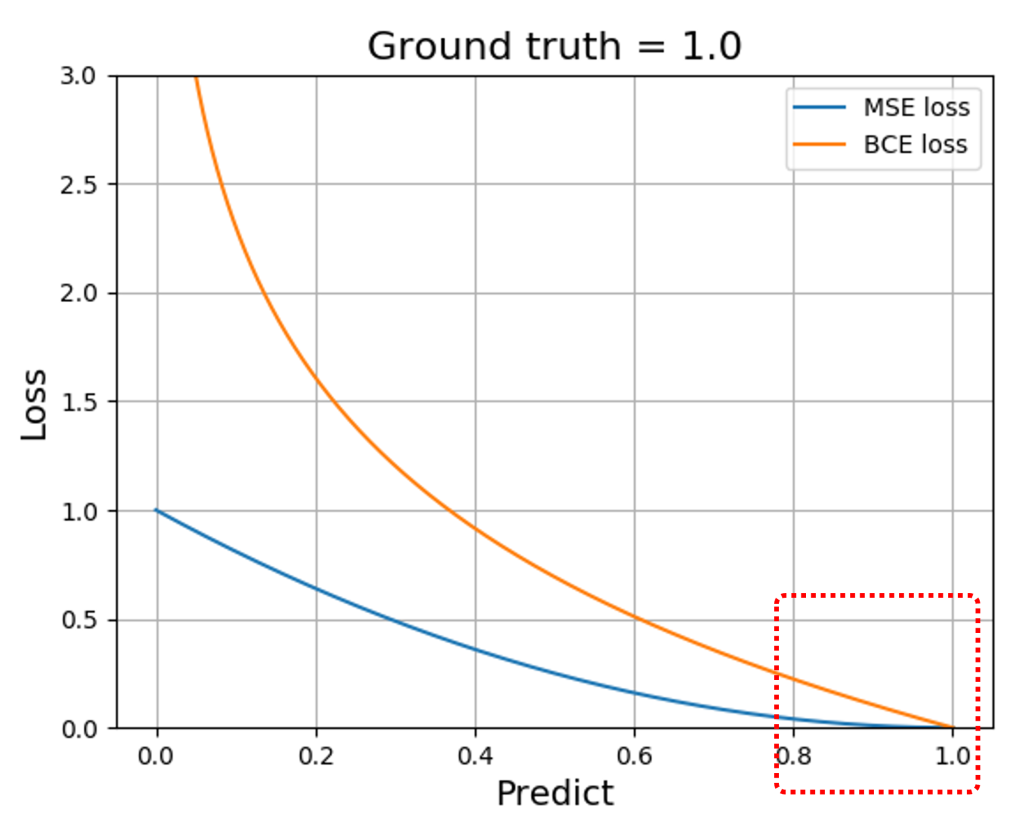
図7 MSE lossとBCE lossとの比較
評価実験
提案したLite-HRNet Plusの性能を評価するため、Lite-HRNetやその他のLight-weightなモデルと比較しました。またデータセットとしてWFLW dataset [6]を使用しました。WFLW datasetはポーズ、表情、イルミネーション、メイク、遮蔽、ピンぼけなどのメタデータに分かれており、場合分けして評価することができます。以下に評価実験の結果を示します。

表1 精度と計算量の比較結果(NMEとFRは小さいほど、AUCは大きいほど性能が良いことを表している)
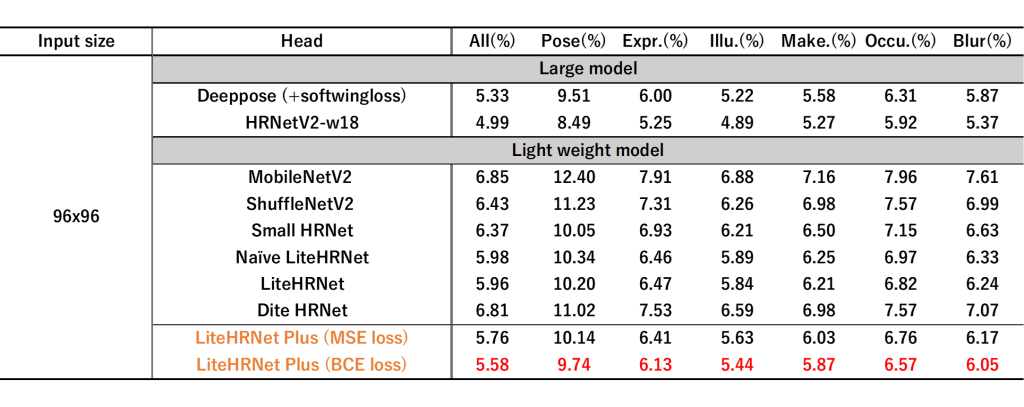
表2 WFLW datasetに含まれる6個のメタデータに対する評価(評価指標はNMEを使用)
表1からLite-HRNetや従来のLight-weightなモデルと比べて、Lite-HRNet Plusの方が精度(NME, FR, AUC)が最も良いことが分かります。また計算量(MFLOPs)を見ても、Lite-HRNet Plusが最も計算量が小さいことが確認できます。表2では6個のメタデータ(Pose, Expr., Illu., Make., Occu., Blur)に対して個別に評価しています。こちらもLite-HRNet Plusが全てのメタデータに対して精度改善を達成しています。またMSE lossよりもBCE lossを使用した方がより精度は改善しており、BCE lossの有効性も確認できました。
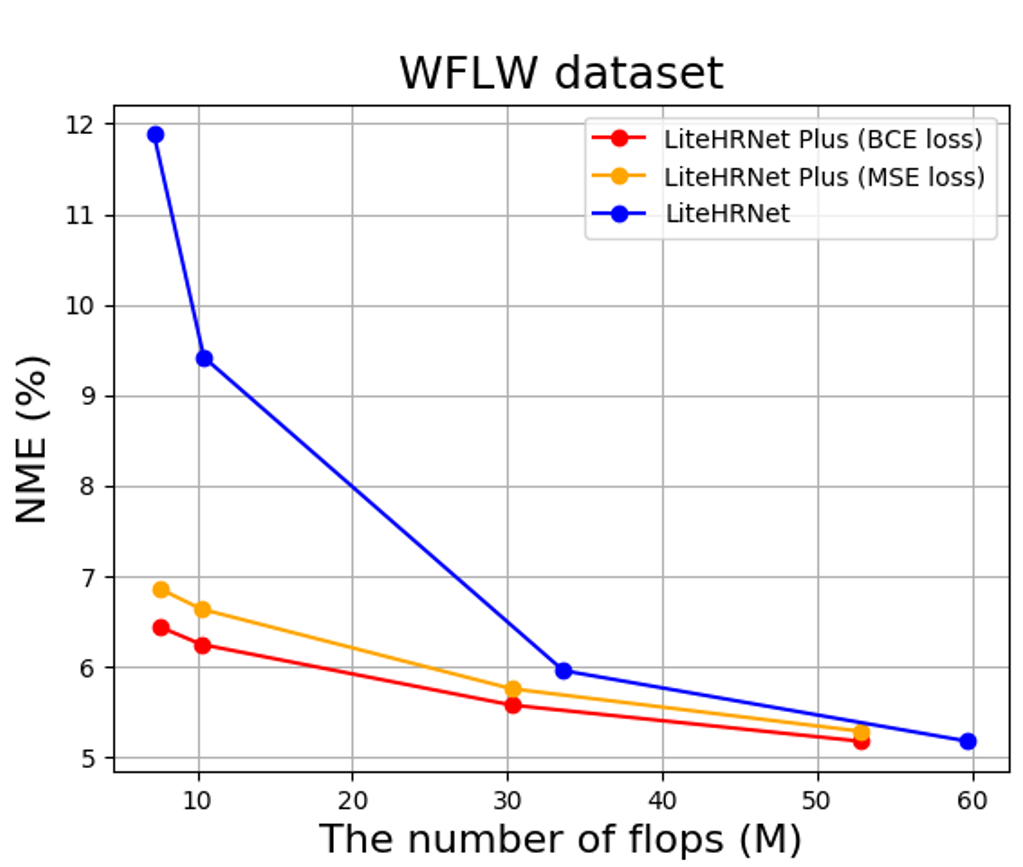
図8 FLOPsを変化させた時のLite-HRNetとLite-HRNet Plusの精度比較
より計算量を減らし、実環境を想定した場合の検証もしました。図8をみると、計算量を減らすほどLite-HRNetは精度が極端に悪化しますが、Lite-HRNet Plusでは精度悪化は緩やかです。ここから低い計算量ほどLite-HRNet Plusがより有効に働くことが分かります。
おわりに
高速・高精度な顔ランドマーク検出が可能な手法であるLite-HRNet Plusを新たに提案し、その有効性を確認することができました。また研究成果をMIRU2022で発表することもできました。インターン中に大変お世話になりました、センスタイムジャパンの社員の皆様に感謝申し上げます。
参考文献
[1] C.Yu, et al. "Lite-hrnet: A lightweight high-resolution network." In Proc. the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.10440-10450, 2021.
[2] N.Ma, et al. "Shufflenet v2: Practical guidelines for efficient cnn architecture design." In Proc. the European conference on computer vision, pp.116-131, 2018.
[3] K.Sun, et al. "Deep high-resolution representation learning for human pose estimation." In Proc. the IEEE/CVF conference on computer vision and pattern recognition, pp.5693 5703, 2019.
[4] K.Sun, et al. "High-resolution representations for labeling pixels and regions." arXiv preprint arXiv:1904.04514, 2019.
[5] X.Wang, et al. "Adaptive wing loss for robust face alignment via heatmap regression." In Proc. the IEEE/CVF international conference on computer vision, pp.6971-6981, 2019.
[6] W.Wu, et al. "Look at boundary: A boundary-aware face alignment algorithm." In Proc. the IEEE conference on computer vision and pattern recognition, pp.2129-2138, 2018.
投稿者プロフィール

-
博士後期課程2年、普段は深層学習を用いた画像認識の研究してます。
2022年4月からリサーチインターンでお世話になっています。

