こんにちは、研究チームの飯田です。
今回はZero-Shot Detectionについての研究動向になります。
論文紹介については、可能な限り手法の中身まで踏み込んで概要説明を行います。近日中に行われる勉強会で大まかな説明をする予定です。概要説明としては細かい気もしますが、その補助資料として利用して頂ければと思います。
Zero-Shot Detectionとは
本章では、大まかなZero-Shot Detectionの仕組みについて概説します。
Zero-Shot Detectionは、未知のクラスの物体検出を行うタスクです。研究分野としては、物体検出とZero-Shot Learningとを組み合わせた研究分野になります。例えば、シマウマの画像を収集できない場合でもシマウマを検出できるようになる研究分野です。
ユースケースとして、専門知識が必要でラベル付けが困難な場合やそもそもデータそのものを収集することが難しい場合に威力を発揮します。ユーザによっては、データの収集時点では想定していなかった新たなクラスを認識したいといったニーズも発生すると思います。そういった場合にも、本記事で解説するZero-Shot Learningでは、推論時に新たに追加したい(未知の)クラス情報を付与するだけで、再学習なしで対処することができるようになります。
次節からは、クラス分類版のZero-Shot Learningの解説からはじめて、その後物体検出版のZero-Shot Detectionの解説をしていきます。
Zero-Shot Learning(分類)
Zero-Shot Learningとは、学習データには無い未知のクラスの認識を目指すタスクです。まずはクラス分類タスクを用いて、Zero-Shot Learningの導入をします。
通常の分類タスクでは、図1のように訓練データのクラス の分類のみを目標にしており、未学習のデータが入力された場合には、既存のクラス
のどれかに分類されます。例えば、クラス集合
からなる訓練データを学習した場合、未知のクラス
は分類できず、
のいずれかに分類されることになります。
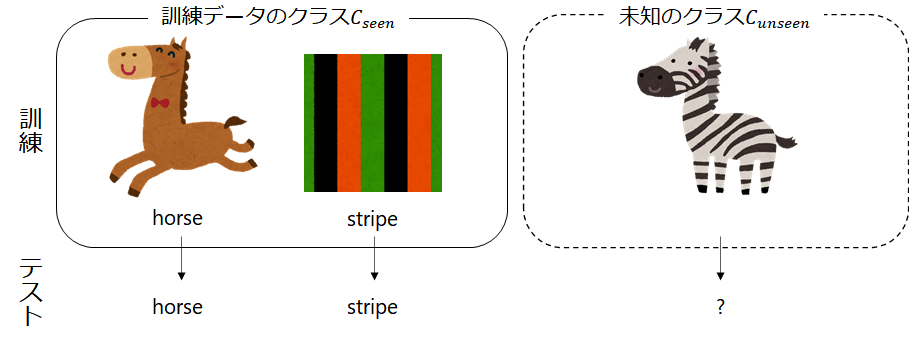
一方Zero-Shot Learningでは、既知クラス のみの学習でも、未知クラス
の分類ができるようにしていきます。昨今では、CLIP [1]などのように大規模データセットから表現学習をしたり、MiDaS[19]のようにデータセットを横断的に学習したりしてZero-Shot Learningする方法が印象的ですが、本記事で取り扱うのは、単語ベクトルから知識を取り込むアプローチです。
上記の 、
の例を使って説明します。
図2は、事前学習済みword2vecモデルからの単語ベクトルを抽出して、Zero-Shot Learningをしている様子です。Zero-Shot Learningのコアとなるアイデアは、視覚特徴(画像特徴、Visual Features)と単語特徴(Semantic Features)との紐付け(アライメント)を行う部分です。アライメントすることで、単語ベクトルの知識を取り込んでいます。単語ベクトルの知識を取り込むことができれば、例えば、"シマウマ" が学習データになくても、「シマウマは、縞柄の馬である」という事前の単語知識を利用できるようになります。画像のエンコーダは、"シマウマ" を入力すると「馬らしい特徴」と「縞柄の特徴」を獲得できるので、適切にアライメントが行えていれば、未学習のシマウマの画像でも"シマウマ"と認識できるようになります。
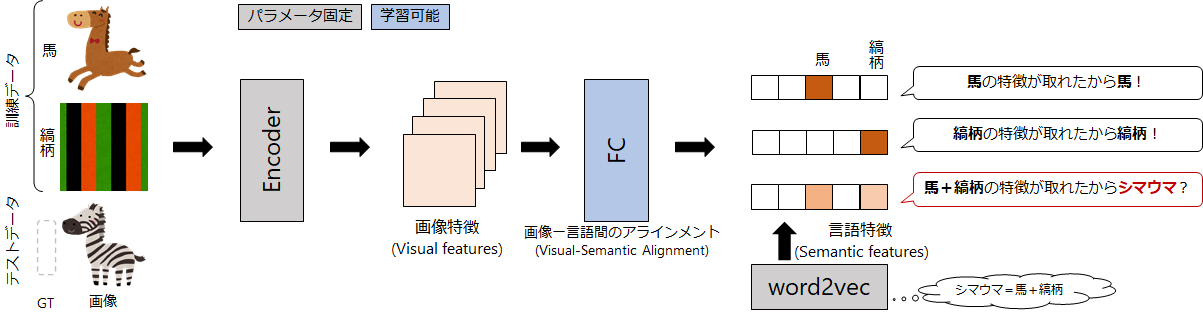
Zero-Shot Learningの評価には主に2つの評価方法があります。それぞれ、未知のクラス"のみ"が正しく認識できるかを評価するのか、既知のクラスも込みで評価して全体としての性能を評価しています。
- Zero-Shot Learning(ZSL): 未知クラスに対する認識性能を測る
- Generalized Zero-Shot Learning(GZSL): 既知クラス+未知クラスに対する認識性能を測る
Zero-Shot Detection
Zero-Shot Detectionは、Zero-Shot Learningを物体検出に応用したタスクです。Zero-Shot Detectionのアプローチには主に、
- 物体検出をした後に各単語ベクトルとの類似度を測るアプローチ
- 未知クラスの画像を生成するアプローチ
の2種類があります。現在は、1. の中でも特に2ステージ検出モデルで類似度を測るアプローチが主流であり、後半の論文紹介でも主に 1. の方法を紹介していきます。
これまで利用する事前学習済みの単語ベクトルはword2vecと述べてきましたが、具体的にはその発展版であるGloVe [13]やfastText[14]を使って学習したものを使っているものが多いです。BLC [4]や Polarity Loss [5], Zero-Shot Instance Segmentation [6] では、Gensimの学習済みのモデルから各単語ベクトルを算出しています。さらに、その単語ベクトルをL2ノルムで正規化すると性能が上がると言われています(参照)。
本記事の本題であるZero-Shot Detectionは、このZero-Shot Learningの物体検出版ですが、クラス分類版の評価項目と同様に、
- Zero-Shot Detection(ZSD): 未知クラスに対する物体検出性能を測る
- Generalized Zero-Shot Detection(GZSD): 既知クラス+未知クラスに対する物体検出性能を測る
という評価項目があります。
Zero-Shot Detectionの難しさ
ここから先の論文紹介でも問題になってきますが、Zero-Shot Detectionは、それぞれのタスクが合わさることで複合的な課題が発生しています。特に筆者が課題と感じるのは、背景クラスに対する対処です。
クラス分類のZero-Shot Learningには、画像中に必ず何らかの物体が存在するという前提がおかれています。一方で、Zero-Shot Detectionは候補領域に必ずしも物体が含まれているとは限らず、物体を含まない領域については、検出結果を背景クラスとして破棄する必要があります。Zero-Shot Detectionは単語ベクトルとの類似度で検出結果を出力するため、検出結果を背景クラスとして破棄するには、背景クラスの単語ベクトルを用意しておく必要があります。どのクラスにも属さない背景クラスの単語ベクトルを決め打ちで用意する(e.g. 全単語ベクトルの平均値)こともできますが、単語空間中に決め打ちの背景クラスを用意すると、イレギュラーな扱いを受けると考えられるので好ましくありません(図3)。ですので、適切な背景クラスの単語ベクトルを用意する必要があり、後ほど紹介する論文でもそれらの対処がなされています。
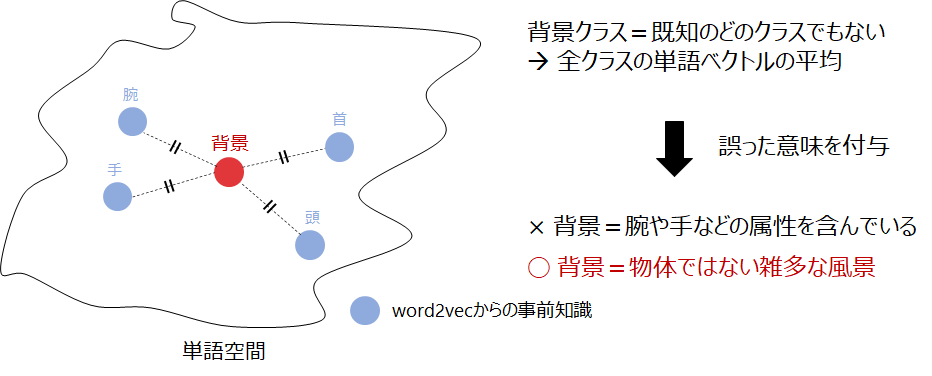
評価方法
評価項目は、ZSDとGZSDがあると述べました。それらの評価項目を測る時の評価指標には、 が利用されます。これは、スコアの高い上位$ K $個のBBoxを描画したときのRecallです。また、未知クラスも既知クラスと同じように扱って、物体認識の標準的な指標である
も同様に利用されています。
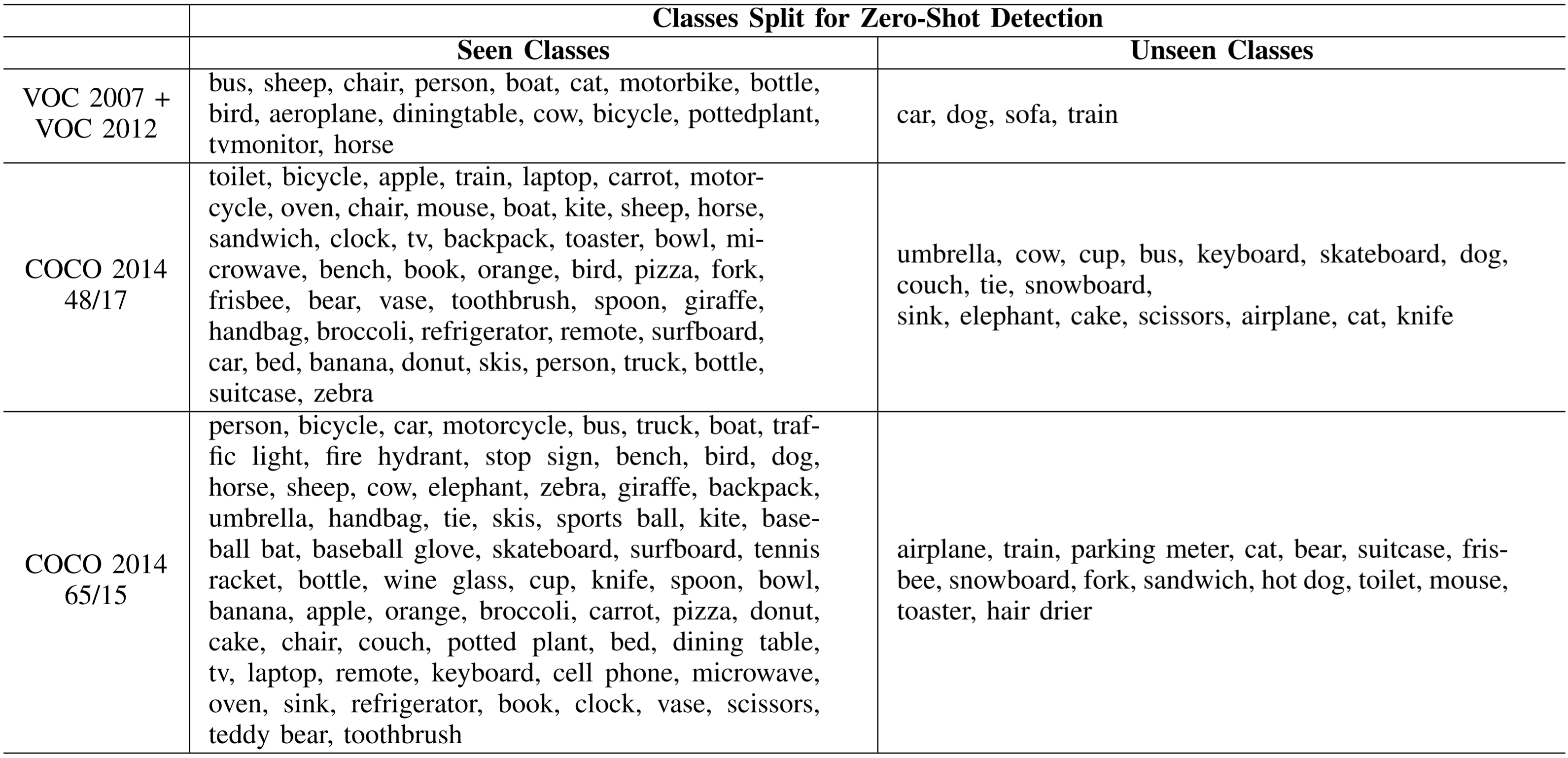
評価用のデータセットには、MS COCOやPascal VOCを既知クラスと未知クラスで分割したデータセットが利用されています(表1)。
論文紹介
ここから、Zero-Shot Detection関連の論文を紹介していきます。
Zero-Shot Object Detection (Bansal+, ECCV, 2018) [2]
本論文がZero-Shot Detection分野の先駆け論文で、MS COCOデータセットを分割して評価する流れなどもこの論文で作られました。
処理の流れは図2と概ね同じで、各BBoxのRoI特徴から単語ベクトルを抽出し、コサイン類似度が最大のクラスを出力結果としています。また、検出のロバスト性に関する工夫も行っています。
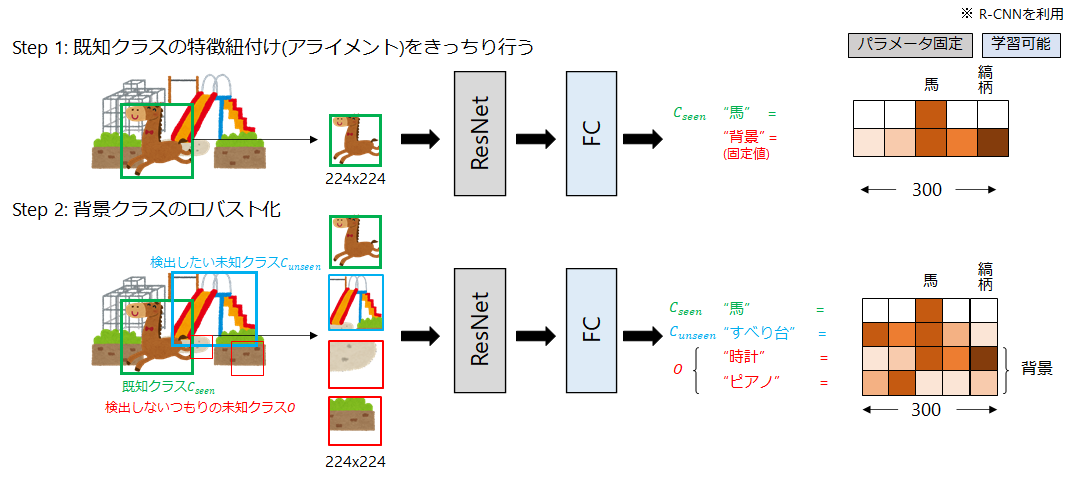
(通常の)物体検出では、分類ヘッドに背景クラスを用意しておくと検出がロバストになることが知られています。Zero-Shot Detectionでもそうしたいのですが、いわゆる「背景」クラスの単語ベクトルをどう準備するのかが課題になってきます。
そこで本論文では、まず背景クラス用にどの単語ベクトルでもない固定の単語ベクトルを作成します。しかし、その単語ベクトルは単語空間(Semantic Space)的に逸脱した表現になっている可能性があります。そこで、EMアルゴリズムベースのLatent Assignment Based(LAB)アルゴリズムを提案して、背景クラスの単語ベクトルを更新しています。具体的には、学習データでBBoxのラベルのついていない領域について、「既知クラス( )」と「検出対象の未知クラス(
)」の両方に属さない「検出予定のない単語(
)」を割り当てて、この領域を何らかの単語にマッピングしています。つまり、背景クラス用の単語ベクトルを複数採用するような更新を行っています。以上の学習ステップをまとめると図4になります。
BLC (Zheng+, ACCV, 2020) [4]
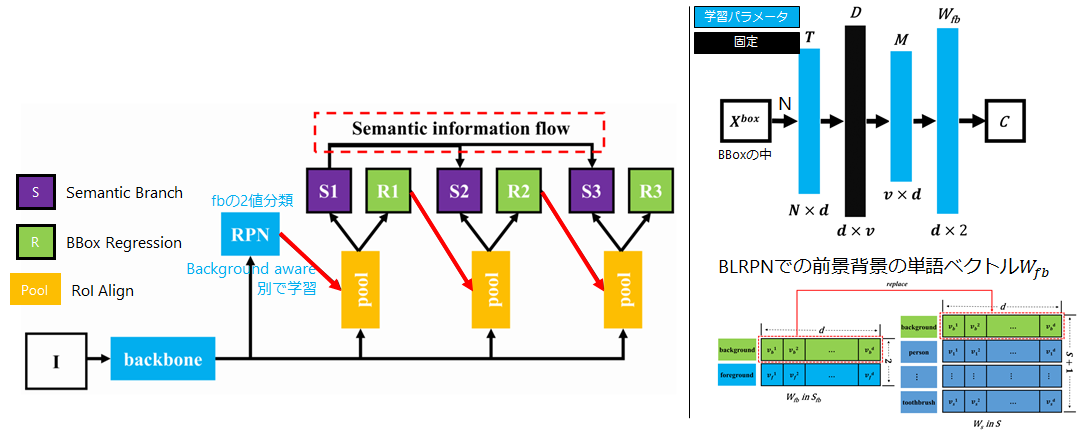
背景クラスの単語ベクトルを学習可能にしたZero-ShotのCascade Faster R-CNN [10]を提案している論文です。
Zero-Shot Object Detection [2]でも背景クラスに対して対処をしていますが、背景クラスの単語ベクトルを学習しているとは言えず、複雑な背景の表現を得ることは難しいと考えられます。Faster R-CNN [11]のRPNは、前景と背景を分けるネットワークなので、本論文では、そのRPNで背景クラスの単語ベクトルを学習できるようにしています。論文中ではこれをBackground Learnable RPN(BLRPN)と言っています。
また、分類やBBox回帰を行う箇所を多段(カスケード構造)にしたことで、BBox回帰やクラス分類結果をステージごとに改善できるようにしています。クラス分類を担うセマンティックブランチの改善では、Semantic information flowの部分で各ステージのセマンティック情報を全結合層を使って改善しています。
全体の構造は図5(左)になっています。
まず、BLRPNの学習を行います。図5(左)のRPN部分では、前景と背景の二値分類を行い、同時に各単語ベクトルとのアライメントを行います。アライメントの方法は図5(右上)の構造になっており、各BBoxの特徴を受け取り、単語ベクトルとのアライメントを全結合層で行います。$ C $は前景か背景かの2クラス分類を行うところでクロスエントロピーが使われます。
BLARNで背景の単語ベクトルの学習を終えたら、それを既知クラスの単語ベクトル( )の一つとして扱って(図5右下)、各セマンティックブランチで画像-単語特徴のアライメントを行います。これにより、学習した背景の単語ベクトルを利用してZero-Shot Detectionが行えるようになります。
Zero-Shot Instance Segmentation (Zheng+, CVPR, 2021) [6]
これは、タイトル通りですが、Zero-Shot Learningのインスタンスセグメンテーション版です。
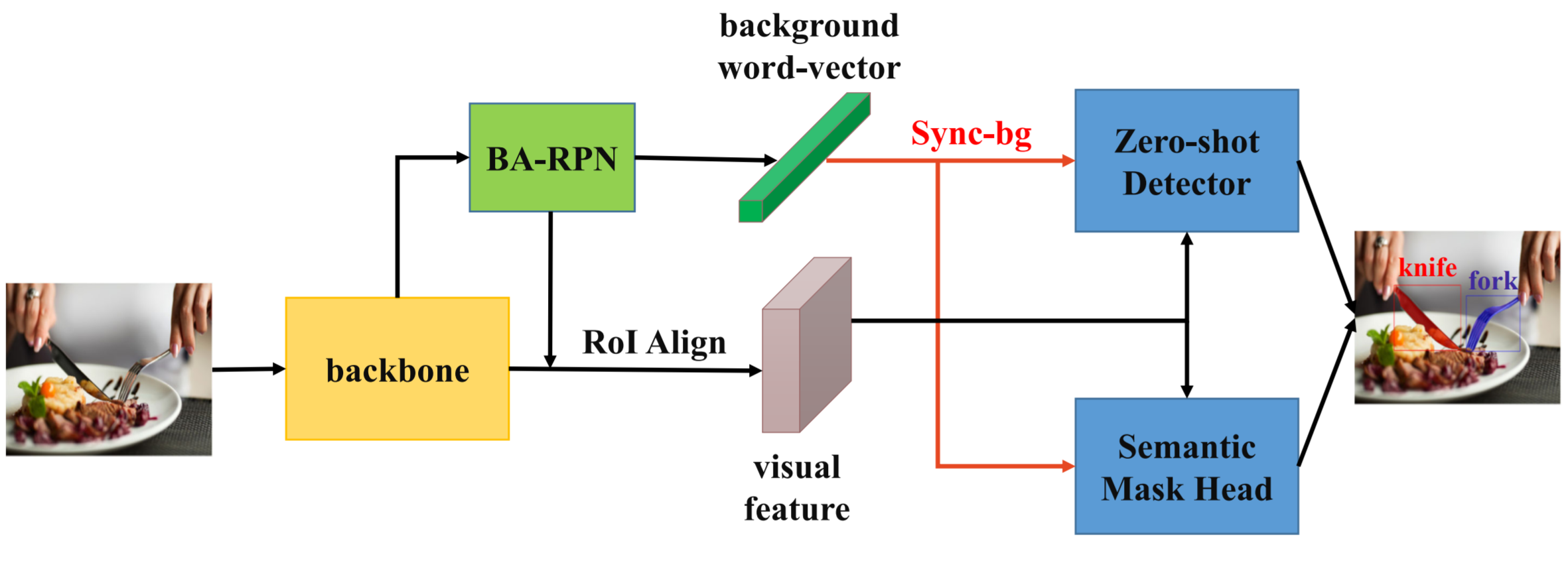
Mask R-CNN [17]をベースとしていることもあって、セグメンテーションだけでなく物体検出も同時に行っています。
全体のモデル構成は図6です。BLC [4]と同じ作者なので、構成モジュールが似ています。BA-RPNというのはBLC[4]のBLRPNと同様に前景と背景の単語ベクトルを事前に学習するモジュールです。
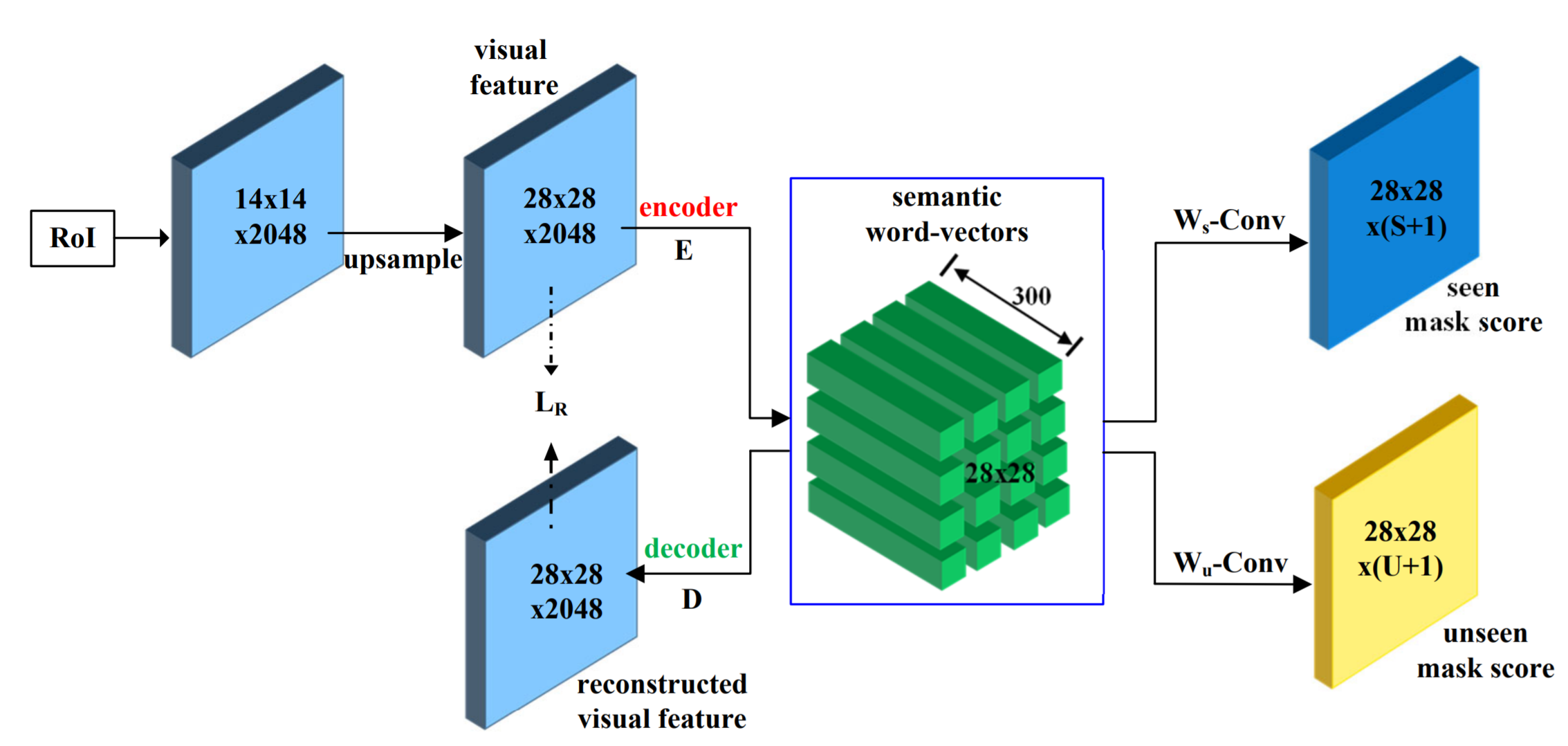
インスタンスセグメンテーションを行うキモはSemantic Mask Headにあります(図7)。通常はRoI特徴について一つの単語ベクトルとのアライメントを行いますが、RoI特徴28x28のピクセルそれぞれで単語ベクトル(300次元)を持たせてピクセル単位でクラス分類ができるようにしています。最後に、 の箇所で、word2vecの既知と未知の単語ベクトルを使って重みを初期化した1x1 Convを使って、ピクセルごとのクラス名を出力しています。
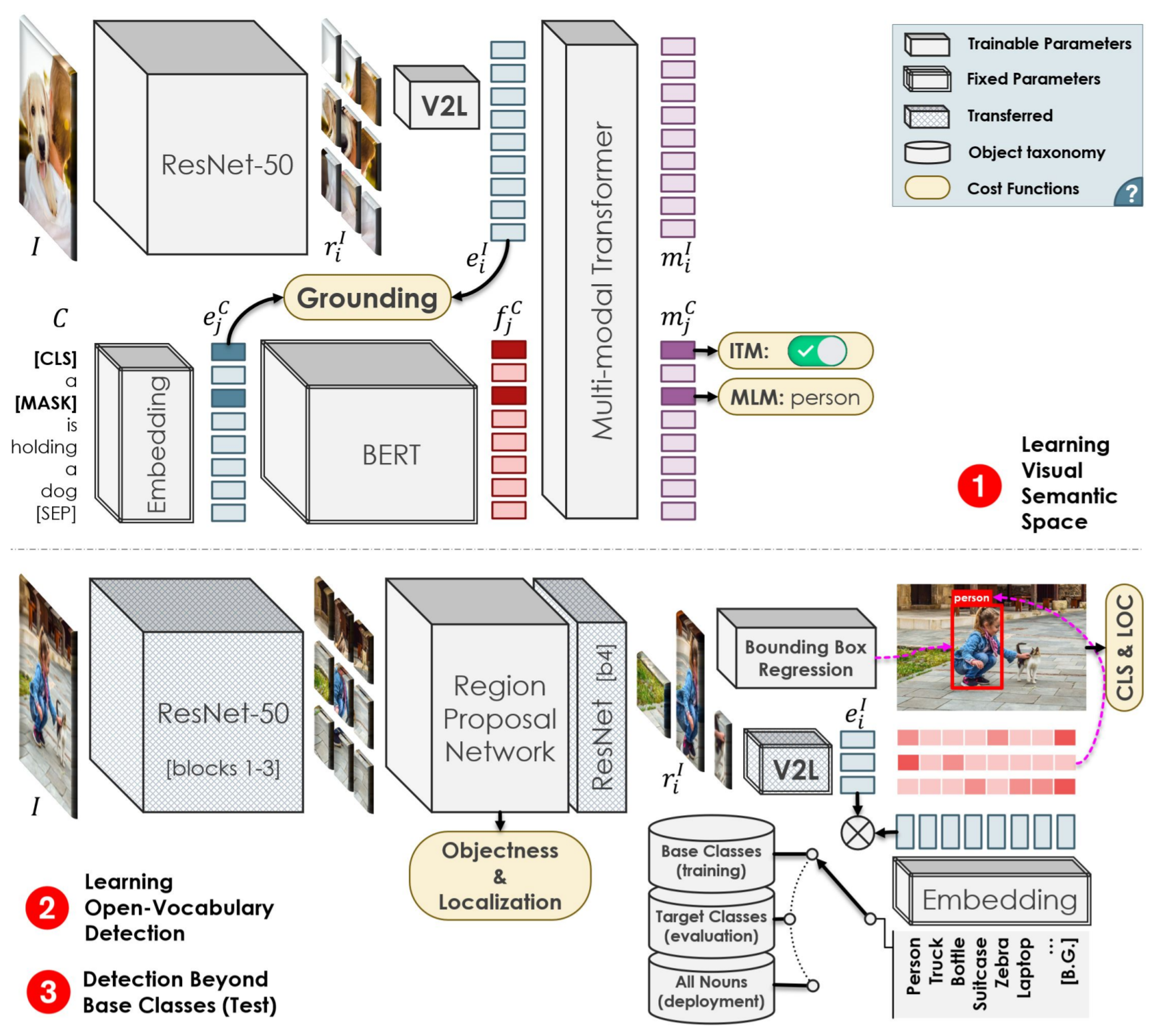
OVD (Zareian+, CVPR(Oral), 2021) [7]
これまではword2vecで学習された単語ベクトルを使って単語関係を利用してきました。ここからは、(誤解を恐れずにいえば)word2vecの発展型であるBERT [15]の単語ベクトルを扱います。例えば、BERTを利用することで、文脈を加味した単語ベクトルを獲得することができるようになります。
本論文では、画像のキャプションデータセット(COCO Captions)を使って、大規模に画像-単語のアライメントの事前学習行うことで性能を向上させています。COCO Captionsのキャプション文には、物体検出データセット(COCO Objects)よりも多くの単語が含まれているため、より広くかつ細かく特徴のアライメントができるようになります。
学習プロセスは以下の流れになっています。それぞれ図8の上段と下段に対応しています。
-
キャプションデータを使った弱教師ありの事前学習
入力は次の2ストリームになっています。- 画像:ResNet[18]でエンコード → 全結合層(
V2L) - テキスト:単語埋め込み(
Embedding)→BERT
この2つのパスを通して得られるテキスト側の単語ベクトル
と画像側の
の単語ベクトル間の類似度を高めていきます(
Grounding)。 - 画像:ResNet[18]でエンコード → 全結合層(
- ダウンストリームタスク(Zero-Shot Detection)でのファインチューニング
意外にも、BERTは画像-単語特徴間のアライメントに直接的には関与しません。BERT入力前の単語埋め込みとのアライメントを行っています。これは、BERTに入力すると単語ベクトルが文脈ごとに変わってしまって、Zero-Shot Detectionを行うには扱いづらいためだと思います。BERTには、以下の2つのサブタスクを行い、1. の(
Grounding)が局所解に陥ることを抑える役割があります。
- Masked Language Model(MTM):
入力テキストの一部を[MASK]とマスキングされた単語位置の「マスクをかける前の単語(図8ではperson)」を予測します。 - Image-Text-Matching(ITM):
画像とテキストがそもそもマッチしているのかを広い視点で(マクロに)捉える役割があります。対照学習(Contrastive Learning)の枠組みを利用して、マッチしている画像-テキストのペアの類似度は最大化、マッチしていないペアの類似度は最小化する学習を行います。
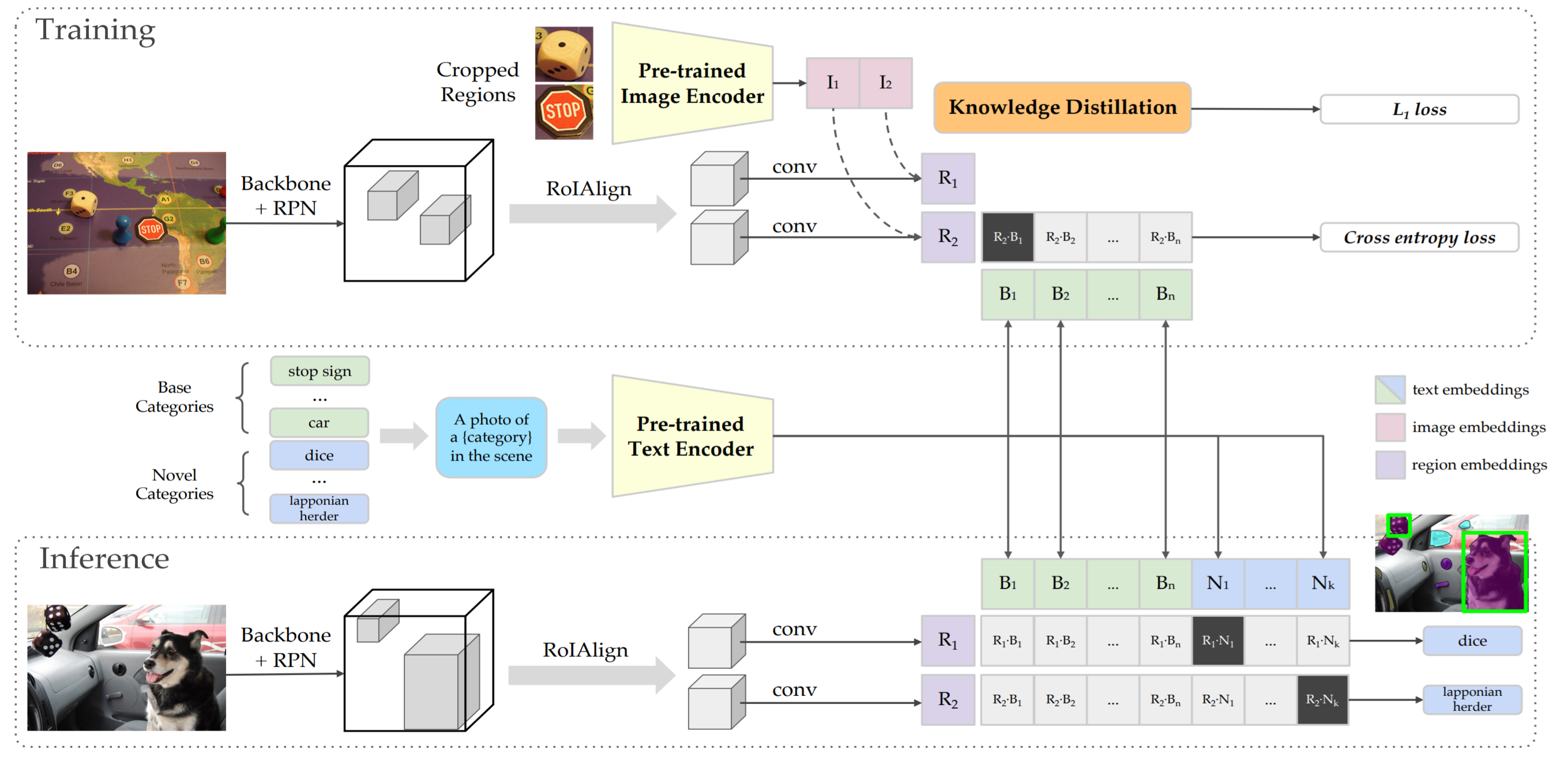
ViLD (Gu+, arXiv:2104.13921) [8]
この論文は、CLIPを蒸留した物体検出モデルを構築した論文です。これまでは、単語ベクトルをword2vecやBERTから得て、その後、画像-単語間の特徴アライメントを行っていました。一方で、CLIPは画像とテキスト間の類似性を大規模データセットで学習したモデルです。CLIP自体がZero-Shotな分類モデルなのですが、そのCLIPを蒸留して、物体検出タスクに応用しています。
全体像を説明します(図9)。
オリジナルのCLIPでは、画像エンコーダとテキストエンコーダがあり、画像とテキスト文との類似性を測り、最も類似度の高いクラスを推論します。ViLDでは、CLIPを物体検出タスクに利用するために、RPNから出力されるRoI Align特徴をCLIPの画像エンコーダに(蒸留して)似せることで、物体検出版のCLIPを作成しています。こうすることで、オリジナルのCLIP本来が持つZero-Shotなクラス分類性能を物体検出に利用しています。
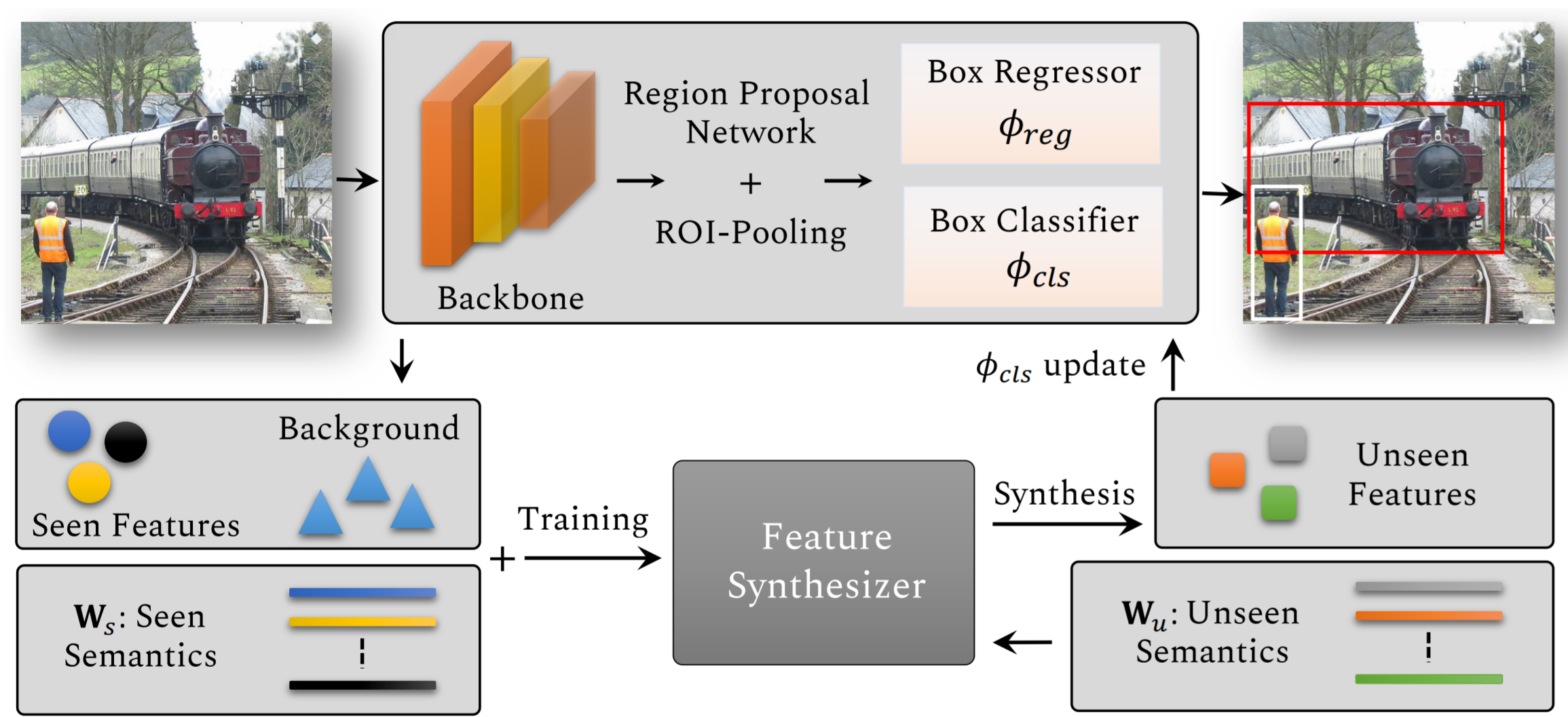
Synthesizing the Unseen for Zero-shot Object Detection (Hayat+, ACCV, 2020) [9]
最後に変わり種で、生成ベースのZero-Shot Detection論文を紹介しようと思います。
生成ベースというので誤解しがちですが、この論文では、実際に画像を生成することは行いません。代わりに、未知クラスの画像特徴を生成して、それを学習しています。
図10に全体像を示します。
上段は、通常のFaster R-CNNです。下段で、未知クラスの特徴生成を行っており、それを使って上段のFaster R-CNNの分類ヘッド(Box Classifier)を更新しています。Feature Synthesizerの中身はWGAN[16]を条件付きに拡張したcWGANです。既知の単語ベクトル を条件としてcWGANを学習することで、未知の単語ベクトル
の画像特徴を生成できるようにしています。
本記事では、Zero-Shot Detectionの研究動向をまとめてみました。各検出結果は載せていませんが、単語関係の情報を使って、画像データが無い状況でも物体検出を行える可能性を示せたと思います。
より発展的な話題として、Visual Grounding (Phrase Grounding)やReferring Expression Comprehension (REC)があります。これらは、単語関係ではなく、テキスト文の文脈情報を活用し、各物体固有の状態(画像中のどの位置にあるか、どんな属性を持っているかなど)も加味した物体検出を行うタスクがあります。それらの発展的話題などを見ても画像-言語のマルチモーダルな手法が近年盛んに研究されており、今後も注目分野になるだろうと思います。
Zero-Shot Learning (Detection)は、画像特徴と単語特徴を紐付けるという点で、マルチモーダル物体検出として入りやすい分野ではないかと思うので、本記事がそれらの理解の助けになれば幸いです。
参考文献
[1] Alec Radford+, "Learning Transferable Visual Models From Natural Language Supervision", arXiv:2103.00020
[2] Ankan Bansal+, "Zero-shot object detection", ECCV, 2018
[3] Sixiao Zheng+, "Incrementally Zero-Shot Detection by an Extreme Value Analyzer", ICPR, 2021
[4] Ye Zheng+, "Background Learnable Cascade for Zero-Shot Object Detection", ACCV, 2020
[5] Shafin Rahman+, "Polarity Loss for Zero-shot Object Detection, AAAI, 2020
[6] Ye Zheng+, Zero-Shot Instance Segmentation", CVPR, 2021
[7] Alireza Zareian+, "Open-Vocabulary Object Detection Using Captions", CVPR, 2021
[8] Xiuye Gu+, "Open-vocabulary Object Detection via Vision and Language Knowledge Distillation", arXiv:2104.13921
[9] Nasir Hayat+, "Synthesizing the Unseen for Zero-shot Object Detection", ACCV, 2020
[10] Zhaowei Cai+, "Cascade R-CNN: Delving into High Quality Object Detection", CVPR, 2018
[11] Shaoqing Ren+, "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks", NIPS, 2015
[12] Tomas Mikolov+, "Efficient Estimation of Word Representations in Vector Space", ICLRW, 2013
[13] Jeffrey Pennington+, "GloVe: Global Vectors for Word Representation", EMNLP, 2014
[14] Piotr Bojanowski+, "Enriching Word Vectors with Subword Information", TACL, 2017
[15] Jacob Devlin+, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding", arXiv:1810.04805
[16] Ishaan Gulrajani+, "Improved Training of Wasserstein GANs", NeurIPS, 2017
[17] Kaiming He+, "Mask R-CNN", ICCV, 2017
[18] Kaiming He+, "Deep Residual Learning for Image Recognition", arXiv:1512.03385
[19] René Ranftl+, "Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer", TPAMI, 2020
投稿者プロフィール
最新の投稿
- 2021.12.22STJOKdoの格安LiDARで遊んでみた
- 2021.12.14STJセンスタイムのXRソフトウェアプラットフォーム「SenseMars」のAR技術について
- 2021.12.10STJ品質よもやま話(その2)~おいしい「品質」~
- 2021.12.09STJ品質よもやま話(その1)~「品質」っておいしいの?~

