
はじめまして、2022年9月から研究開発センターのインターンとしてお世話になっている、玄元と申します。
本記事ではインターン期間中に取り組んだ研究内容である、骨格推定ベースのレーン検出手法「LanesPose」について解説させていただきたいと思います。
なお。この成果は2023年7月25日〜7月28日に開催される第26回 画像の認識・理解シンポジウム(MIRU2023)にて発表予定です。
はじめに

図1: レーン検出の例(Eigen Lanes[1]より引用)
研究背景

図2: オクルージョン(左)と夜間(右)のシーン。
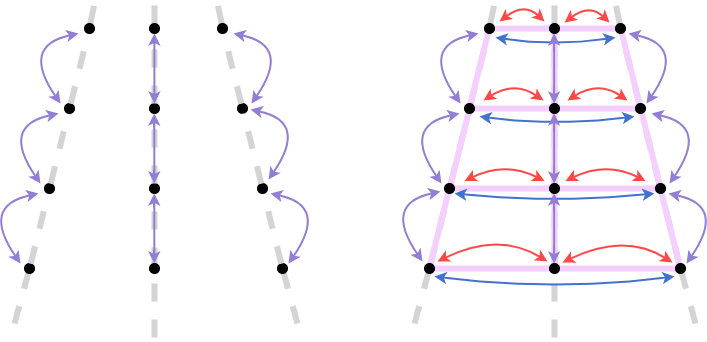
図3: 従来手法と既存手法のイメージ図。左側が従来手法、右側が手案手法であるLanesPoseを表している。
骨格推定
骨格推定とは画像から人体や動物の体などの関節をキーポイントとして検出し、その接続関係を推定する技術です。キーポイントの位置という局所的な情報と骨格全体の形状という大域的な情報を同時に扱います。

図4: PifPafのCIFとCAF([6]より引用)。図左が左肩のPIF、図右が左肩と左腰のPAFをそれぞれ表している。
LanesPoseでは、レーンの局所的な位置情報と大域的な形状情報をOpenPifPafのCIFとCAFで扱うことによってレーンを検出しています。
LanesPose(提案手法)
LanesPoseは骨格推定ベースの手法に影響を受けており、2つのアイデアから成り立っています。
幾何的重要性に基づくキーポイント抽出
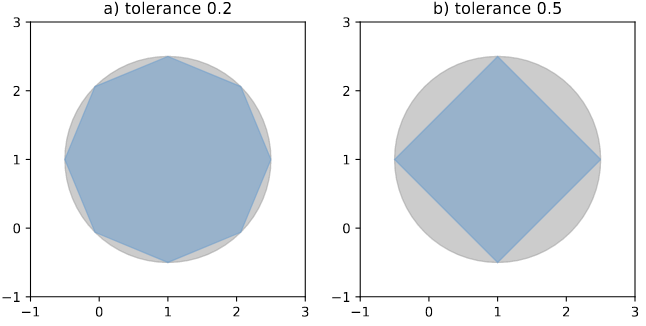
図5: Shapelyを用いた図形の単純化([8]より引用)。
そこで、レーン構造上重要な点をDouglas-Peuckerアルゴリズム[9]を用いた図形の単純化(Simplification)によって決定し、重みを大きくしてモデルの学習を行っています。実装にはShapely[10]というライブラリを用いており、Shapelyを用いた図形の単純化のイメージが図5です。LanesPoseにおいて使用しているキーポイントの重みをサイズに反映させて可視化したものが図 6になります。

図6: 幾何的重要性に基づくキーポイントの重み付け結果を可視化した画像。重要度が高い順に赤>橙>黄緑>青と色付けしている。
動的な骨格定義

図7: 定義した接続関係を可視化した画像。レーン内の接続(intra)を赤、レーン間(inner)の接続を多色、対応点が画面外にある場合の接続を青点線で描画している。
また、「隣接レーンの最寄りのキーポイントと接続する」という一貫性を持たせるために、接続のペアの決定にはDynamic Time Warping(DTW)[11]という手法を用いています。
DTWとは時系列データ同士の距離を測る際に用いられる手法で、2つの時系列の各点の距離を総当りで求め、最短となる経路を見つける手法です。
LanesPose ではレーン内 (intra) の接続とレーン間 (inter) の接続を考えており、定義した接続関係を可視化したものが図 7になります。
評価実験
評価用のデータセットにはCULane[12]を使用しました。CULane は高速道路や街中を車載カメラから撮影した走行データセットで、訓練用 88, 800 枚、検証用 9, 675 枚、テスト用 34, 680 枚の計 133,235 枚が収録されている大規模なものとなっています。
また、テストデータはカーブや夜間、交差点など レーン検出が難しいシーンを含む9 つのカテゴリーに分かれています.
提案したLanesPoseの有効性を検証するためにキーポイントの接続と重みに関して複数の異なる組み合わせ実験を行いました。
- レーンの数
- レーン骨格の接続情報を考慮せずキーポイントのみの場合
- 一本のレーンを一つの骨格とする場合
- 複数のレーンをまとめて一つの骨格とする場合
- 接続方法
- 各レーンを手前側から奥にかけて採番したとき,複数のレーンにおいて手前から同じ番号にあたる点同士を決定的に接続した場合 (Static)
- DTW を用いて接続元と接続先のキーポイント系列において距離的に近いもの同士を動的に接続した場合 (Dynamic)
- キーポイントの重み
- 全て同じ重要度とする場合
- 幾何的重要性に基づき重み付けした場合 (simplification)
それぞれの場合において評価した結果を表1に示します。
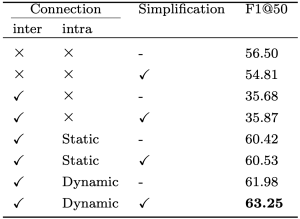
表1: ablation study
CULaneの全テストデータを用いて、比較のためにバックボーンのモデルは全てResNet18に統一して検証いたしました。
DTW を用いた動的な接続に加え,幾何学的重要性に基づいた重みづけを行なった場合において性能が向上し、それぞれの手法の有効性を確認することができました。
また、図8に示すようにレーン毎に独立して推論した場合に比べ、複数のレーンを考慮して推論した場合において優れた結果が得られました。特にオクルージョンクラスにおいては右端のレーンが完全に隠蔽されており、隣接レーンとの接続を考慮することにより、隠されていて情報のないレーンを検出することができたと考えられます。

図8: LanesPose の比較図。レーン独立の場合に比べて,レーン連結の場合において検出精度が向上している。
応用例
LanesPoseは骨格推定ベースの手法のため、[13]のように二次元座標の推定から三次元座標の推定へと拡張を行うことによって3Dレーン検出に拡張できると考えます。また、従来の骨格推定とは異なり、レーンと同時に別のロードインスタンスを扱うことができる点が強みです。レーンと同時に三角コーンやガードレールなどを同時に検出することにより、工事現場の領域推定などにも応用が期待できます。
おわりに
幾何的に重要なキーポイントと動的な接続を用いて学習する手法と複数のレーンを考慮したレーン検出手法であるLanesPose を提案し、その有効性を確認しました。
また、この研究成果をMIRU2023において発表することになり、嬉しく思います。当日はぜひ会場に遊びに来てください!
そしてインターン期間中に大変お世話になりました、センスタイムジャパンの社員の皆様にこの場を借りて心より感謝を申し上げます。
参考文献
[1] Dongkwon Jin, Wonhui Park, Seong-Gyun Jeong, Heeyeon Kwon, Chang-Su Kim.: Eigenlanes: Data-Driven Lane Descriptors for Structurally Diverse Lanes, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17163-17171 (2022).
[2] Abualsaud, H., Liu, S., Lu, D. B., Situ, K., Rangesh, A. and Trivedi, M. M.: Laneaf: Robust multi-lane detection with affinity fields, IEEE Robotics and Automation Letters, Vol. 6, No. 4, pp. 7477–7484 (2021).
[3] Qu, Z., Jin, H., Zhou, Y., Yang, Z. and Zhang, W.: Focus on local: Detecting lane marker from bottom up via key point, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14122–14130 (2021).
[4] Xu, S., Cai, X., Zhao, B., Zhang, L., Xu, H., Fu, Y. and Xue, X.: RCLane: Relay Chain Prediction for Lane Detection, Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVIII, Springer, pp. 461–477 (2022).
[5] Cao, Z., Simon, T., Wei, S.-E. and Sheikh, Y.: Realtime multi-person 2d pose estimation using part affinity fields, Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7291–7299 (2017).
[6] Kreiss, S., Bertoni, L. and Alahi, A.: Pifpaf: Composite fields for human pose estimation, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11977–11986 (2019).
[7] Kreiss, S., Bertoni, L. and Alahi, A.: Openpifpaf: Composite fields for semantic keypoint detection and spatio-temporal association, IEEE Transactions on Intelligent Transportation Systems, Vol. 23, No. 8, pp. 13498–13511 (2021).
[8] https://shapely.readthedocs.io/_/downloads/en/1.8.1/pdf/
[9] Visvalingam, M. and Whyatt, J. D.: The Douglas-Peucker algorithm for line simplification: re-evaluation through visualization, Computer Graphics Forum, Vol. 9, No. 3, Wiley Online Library, pp. 213–225 (1990).
[10] https://github.com/shapely/shapely
[11] Dynamic Time Warping, pp. 69–84, Springer Berlin Heidelberg (2007).
[12] Pan, X., Shi, J., Luo, P., Wang, X. and Tang, X.: Spatial as deep: Spatial cnn for traffic scene understanding, Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32, No. 1 (2018).
[13] Chen, Ching-Hang and Tyagi, Ambrish and Agrawal, Amit and Drover, Dylan and MV, Rohith and Stojanov, Stefan and Rehg, James M.: Unsupervised 3D Pose Estimation with Geometric Self-Supervision, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5714--5724 (2019).
投稿者プロフィール
-
博士前期課程2年、普段は深層学習を用いた歌声変換の研究をしています。
2022年9月から研究開発チームのインターンとしてお世話になっています。
