こんにちは、センスタイムジャパンの畠山です。センスタイムジャパンでは産学連携の取り組みをおこなっており、そのひとつに、京都大学の末永准教授との共同研究があります。その論文が、15th Asian Conference on Computer Vision (ACCV2020) に採択決定いたしました。
本記事では上記論文 "Visualizing Color-wise Saliency of Black-Box Image Classification Models"[1] の内容をご紹介したいと思います。
はじめに
本研究では、ブラックボックスな画像分類モデルに対して、入力画像中の「画素の色」の重要度を可視化することでモデルの判断根拠を説明する手法、Multi-Color RISE (MC-RISE)を提案しました。MC-RISEでは、入力画像の一部をを様々な色でマスクした場合のモデル出力の反応を調べることで、「画素の色」の重要度を可視化する事ができます。
機械学習モデルの判断根拠説明手法
まず初めに、機械学習モデルの判断根拠を説明する手法についていくつか紹介したいと思います。
機械学習モデルの説明手法には様々なアプローチがありますが、ここではFeature attributionと呼ばれるアプローチについて紹介します。Feature attributionでは、1つの入力データとそれに対するモデルの出力結果について、「この入力データのどの部分がモデルにとって重要な判断根拠になったか」という情報を抽出します。よく知られたFeature attribution手法としては、LIME[2], SHAP[3], Grad-CAM[4]等が挙げられます。

特に画像認識モデルに対するFeature attribution手法では、顕著性マップ(Saliency map)という形で入力データの重要度を可視化する事が多いです。上の図1は、Grad-CAM[4]による顕著性マップの例を示していて、顕著性マップが大きい値を持っている領域ほどモデルの判断根拠への重要度が高い事を表しています。「Cat」のクラスに対しては画像中の猫の領域が、「Dog」のクラスに対しては画像中の犬の領域の重要度が高い事が分かります。
Feature attribution手法はさらに、ホワイトボックスモデルに対する手法とブラックボックスモデルに対する手法に分類できます。
ホワイトボックスモデルに対する手法では、モデルの内部構造の情報(例:誤差逆伝播法による勾配計算)を利用してモデルの判断根拠を推定します。そのため、手法ごとに特定の構造を持った機械学習モデルに対してのみ適用可能です。
一方ブラックボックスモデルに対する手法では、モデルの内部構造の情報は用いず、モデルの入力・出力関係の情報のみを使用してモデルの判断根拠を推定します。そのため、任意の種類の機械学習モデルに適用する事ができるという利点があります。本研究の提案手法 MC-RISE もブラックボックスモデルに対する手法です。
RISE の説明
本研究の手法は、既存のFeature attribution手法であるRISE[5]をベースに改良を加えたものとなっています。そこで、RISEのアルゴリズム(図2)について説明したいと思います。
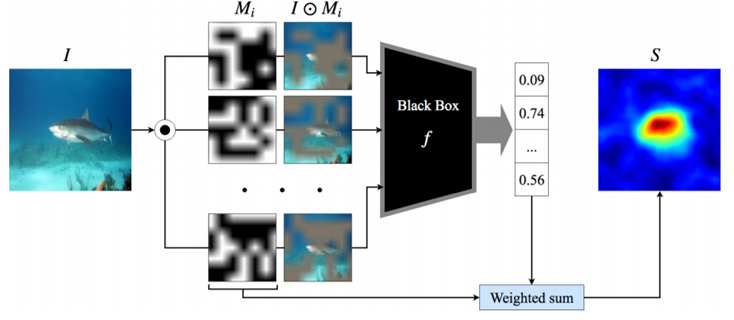
RISEでは、「入力画像に改変を加えた際にモデルの出力がどのような反応を示すか」というデータを収集することで、入力画像の各領域の重要度を推定します。具体的には、入力画像($I$)をグリッドに分割し、各グリッドをランダムにマスクした画像($I \odot M_i$)を多数生成します。そしてこれらの画像をモデル($f$)に入力して、ターゲット・クラスへの出力信頼度のデータを収集します。
これらのデータから重要度を抽出するための基本的な考え方は、
- もしモデルの判断にとって重要な物体がマスクされれば、出力信頼度は大きく下がるはず
- 逆にモデルにとって重要度が低い背景部分がマスクされても出力信頼度はさほど変化しないはず
といったものです。
この考え方に従うと、入力画像改変に使用したマスク群($M_i$)を対応する出力信頼度を重みとして重み付き平均をとることで、重要度が高い領域が大きな値を持つ顕著性マップを得る事ができます。このようにして、モデルにとって画像中の「どの場所が」重要であるかを可視化する事ができます。
提案手法
本研究では上記のRISEのアルゴリズムを拡張し、「どの場所が」重要であるかだけではなく、その場所の「色」の重要度も一緒に抽出できるように改良した手法、MC-RISEを提案しました。

RISEでは入力画像をマスクする際に単一の色でマスクしていましたが、MC-RISEではマスクに使う色も(事前に設定した色セットの中から)ランダムに決定します。その結果、図3のようにグリッドごとに異なる色でマスクされた画像が多数生成されます。このような画像群をモデルに入力して得た出力信頼度のデータを統合することで、「モデルが色の変化に対してどのような反応を示すか」という情報を可視化することができます。
またRISEにおいては、モデルの分類に影響を与えない背景部分の顕著性マップの値が画像ごとに異なり、重要な物体とそうでない背景部分のしきい値を切る事が難しい場合がありました。MC-RISEでは、このような顕著性マップのバイアスを取り除く手法を組み込んでおり、背景部分での顕著性マップの値が常にほぼ0となる顕著性マップが得られます。

図4では、ドイツの交通標識画像を分類するモデルに対するMC-RISEの顕著性マップの例を示しています。赤色に対する顕著性マップに注目すると、「STOP」文字の周囲の部分で顕著性マップが正の値を取っています。これは、「STOP」文字周囲が赤色である事で"Stop"標識クラスへの信頼度が上昇する事を示しています。一方で、他の色に対する顕著性マップは標識全体で負の値を取っています。これは、もしも標識に赤以外の色が混じっていた場合、"Stop"標識クラスへの信頼度が減少する事を示しています。これらの事から、モデルがこの画像を"Stop"標識クラスに分類するにあたって、「STOP」文字周囲が赤色である事が重要な判断根拠となっている事を読み取る事ができます。
さらなる詳細については、arXiv論文[1]、あるいは2020年11月30日から開催予定のACCV2020での私達の研究発表をご覧ください。
参考文献
[1] Y. Hatakeyama, H. Sakuma, Y. Konishi, and K. Suenaga, “Visualizing Color-wise Saliency of Black-Box Image Classification Models,” arXiv:2010.02468 [cs], 2020.
[2] M. T. Ribeiro, S. Singh, and C. Guestrin, “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016.
[3] S. M. Lundberg and S.-I. Lee, “A Unified Approach to Interpreting Model Predictions,” in Advances in Neural Information Processing Systems 30, 2017.
[4] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017.
[5] V. Petsiuk, A. Das, and K. Saenko, “RISE: Randomized Input Sampling for Explanation of Black-box Models,” in Proceedings of the British Machine Vision Conference (BMVC), 2018.
投稿者プロフィール
-
研究開発センター 研究チーム所属 リサーチャー。博士(理学)。
趣味は主に科学関係の読書。
最新の投稿
- 2022.06.01STJ統計検定1級受験記
- 2021.12.17STJRendering 3D Fractals by Sphere Tracing
- 2021.12.13STJエッジAIコンピューティングについて
- 2021.10.06STJセンスタイムによるCVPR2020発表論文: DNN枝刈り(Pruning)手法 「DMCP」を紹介します